

AI 기반 이미지 생성 모델은 빠르게 발전하고 있지만, 여전히 의심스러운 이미지를 생성하는 경우가 많습니다. 인간의 프롬프트가 문제라고 생각하기 쉽기 때문에, AI가 생성한 프롬프트만 사용할 때 AI의 성능이 더 향상되는지 테스트해 보기로 했습니다. ChatGPT나 Gemini와 같은 AI 이미지 생성은 프롬프트의 품질과 정확도에 크게 의존합니다. 자동화된 프롬프트를 사용하면 결과가 달라질까요? 이 실험을 통해 알아보도록 하겠습니다.
![]()
경험 법칙
몇 년 전 AI 이미지 생성 모델이 등장했을 때, 우리는 모두 이것이 시각 미디어 업계 종사자들에게 경종을 울릴 것이라고 생각했습니다. 하지만 사실은 그렇지 않았습니다. AI 이미지는 매우 사실적인 이미지를 생성할 수 있음에도 불구하고, 특히 더 복잡한 이미지가 필요한 경우 예상치 못한 범주에 속하는 경우가 많습니다(예: AI는 손 이미지 생성에 어려움을 겪는 경향이 있습니다).
이 문제에 대해 AI 모델 자체를 비난할 수도 있고, 인간의 단점과 일관성 없는 프롬프트 작성 능력을 비난할 수도 있습니다. 누구의 잘못인지 확인하는 가장 자연스러운 방법은 이미지 생성 모델에 생성 프롬프트를 도입했을 때 더 나은 결과를 도출하는지 확인하는 것입니다.

AI가 역사적 순간에 대한 새로운 관점을 제공할 수 있을까?
이 가설을 검증하기 위해 Gemini를 사용하여 만들려는 객체나 이미지의 이름을 사용하지 않는 일련의 프롬프트를 생성할 것입니다. 이를 통해 AI가 명령을 얼마나 잘 "읽는지" 확인할 수 있습니다. 물론, 모델이 훈련된 데이터에서 상당한 영감을 얻을 가능성은 여전히 있지만(특히 기존 이미지를 재현할 때), 그것이 현실이라고 Young은 말합니다.
제가 이미지를 만드는 데 선택한 도구는 Bing(네, Bing은 아직 존재합니다)의 Image Creator입니다. 이 도구는 DALL-E 3를 기반으로 합니다. 모델을 테스트하기 위해 간단한 모양으로 시작한 다음 실험이 진행됨에 따라 더 복잡한 이미지로 넘어갈 것입니다.
ChatGPT나 비슷한 도구를 사용해 보셨다면 일부 답변이 얼마나 비효율적인지 이미 알고 계실 겁니다. "베타" 테스트 기간 동안 모델이 제시한 질문들도 마찬가지였습니다. 그래서 질문의 일관성을 유지하기 위해 500자로 제한하기로 했습니다.
AI가 간단한 모양을 처리하는 방법
간단한 정사각형부터 시작해 볼까요? 제미니에게 정사각형의 이름을 적지 않고 설명해 보라고 했더니, 제미니는 다음과 같은 답을 내놓았습니다.
모든 변의 길이가 같은 사각형입니다. 각 내각의 크기는 정확히 90도입니다. 마주 보는 변이 평행한 정사각형입니다.
DALL-E에 설명을 입력한 후 다음과 같은 결과를 얻었습니다.
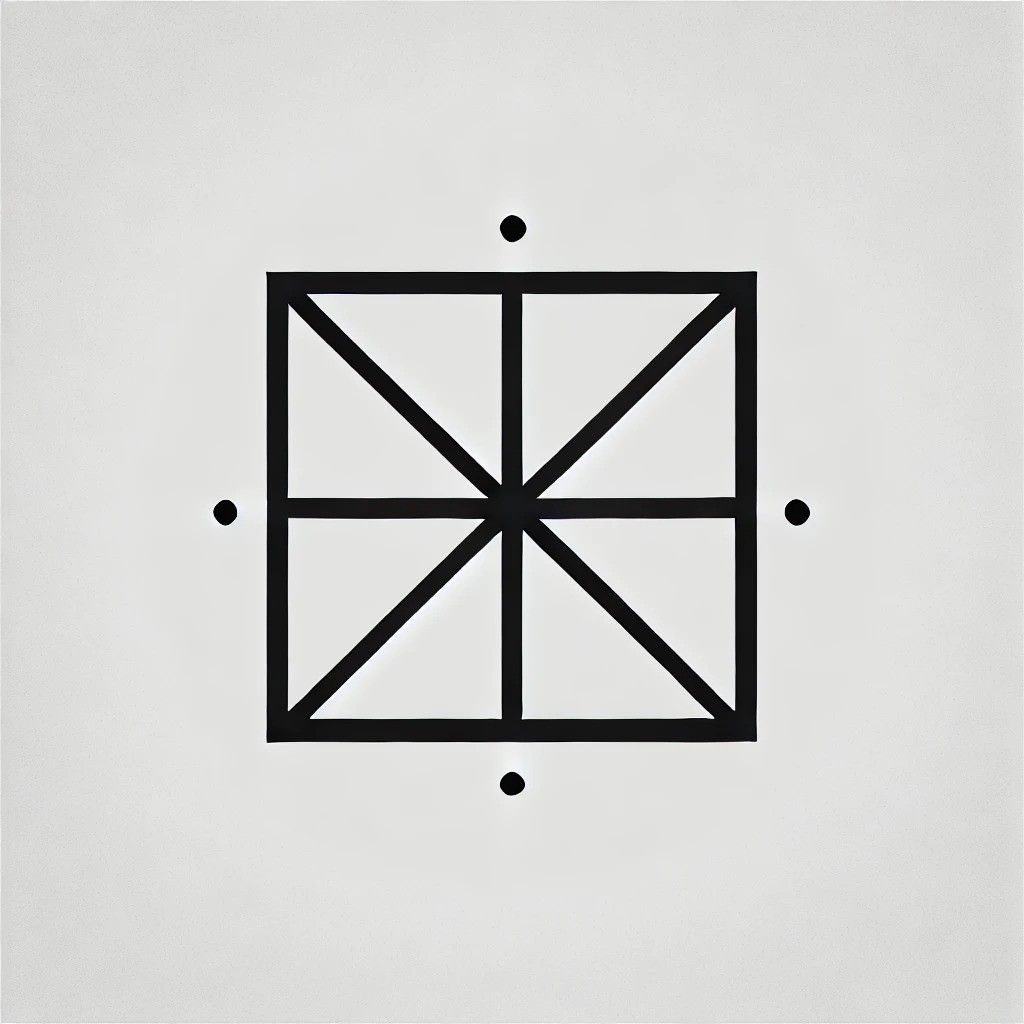
네, 정사각형이에요. 하지만 좀 너무 기하학적인 것 같아요. 이제 좀 더 발전시킬 때가 되었다고 생각해서 AI에게 정육면체를 자세히 그려달라고 부탁했어요.
여섯 개의 합동하는 면을 가진 3차원 도형입니다. 각 면은 네 개의 변과 네 개의 직각을 가진 정사각형입니다. 길이가 같은 변이 12개, 꼭짓점이 8개 있습니다. 도형 내의 모든 각은 직각입니다.
결과는 놀랍습니다.

AI 모델의 예측 불가능성에 대해 말씀드렸던 것 기억하시나요? 자, 여기서 DALL-E는 큐브를 만들다가 약간 헷갈려서 루빅큐브로 만들었습니다. 정확한 단어를 전혀 사용하지 않았음에도 불구하고, AI는 부분적으로 틀렸습니다. 이는 은하계 퍼즐 게임의 인기에서 기인한다고 할 수 있습니다.
사람과 함께 사진을 찍는 AI
큐브의 상황은 정확하고 "편견 없는" 설명을 하더라도 AI가 상당히 간단한 지시를 잘못 해석할 수 있음을 보여줍니다. 자, 도로시어 랭의 "이주하는 어머니"와 같은 고전적인 이미지에 대한 AI의 설명이 얼마나 효과적인지 살펴보겠습니다. 원본 이미지는 다음과 같습니다.

걱정으로 가득 찬 한 여인이 카메라에서 시선을 돌립니다. 그녀 주변에는 얼굴을 가리거나 얼굴을 돌린 아이들이 있습니다. 그녀의 손은 얼굴에 바싹 붙어 피로와 괴로움을 드러냅니다. 이 장면은 가난과 고통을 암시합니다. 여인의 옷차림은 초라하고, 전체적인 구도는 어둡게 표현되어 그녀가 처한 상황의 심각성을 강조합니다.
이는 DALL-E가 상상한 유명한 이미지입니다.

아주 가깝습니다! 하지만 DALL-E가 "그녀의 자녀들에 둘러싸여 있었는데, 그들의 얼굴은 가려져 있거나 돌아서 있었습니다."엄마"가 얼굴 가까이에 손을 대는 대신, 아이 중 한 명이 이 역할을 맡았습니다.
좀 더 복잡한 것을 시도해 볼까요? 유명한 사진 "고층 빌딩 꼭대기에서 점심 식사"를 보셨을지도 모르겠네요.

열한 명의 남자가 높은 곳, 철제 기둥 위에 앉아 다리를 축 늘어뜨리고 점심을 먹고 있다. 기둥은 광활한 도시 위에 매달려 있다. 남자들은 고도가 매우 높음에도 불구하고 편안해 보인다. 그들은 정장을 입고 있으며, 이 장면은 약간 낮은 각도에서 촬영되어 키가 더 강조되었다.
이 위대한 주장은 훌륭한 결과를 가져왔습니다.

AI가 생성한 이미지의 전형적인 특징(똑같은 도자기와 "복사해서 붙여넣은" 피사체)을 무시하면, 구도와 전반적인 느낌 면에서 거의 놀랍습니다. 하지만 놀랄 일은 아닙니다. 이 이미지는 매우 인기가 많을 뿐만 아니라 퍼블릭 도메인이기 때문에, DALL-E가 훈련 과정에서 실제로 내용을 복구했을 것이라는 은근한 의심이 듭니다.
AI가 복잡한 이미지를 처리할 수 있을까?
이번 실험의 마지막 "테스트"인 만큼, 본격적으로 시작할 시간입니다! AI는 사람 이미지를 처리하는 데는 능숙하지만, 복잡하고 모호한 장면에서는 종종 실패합니다. 아폴로 8호가 달 궤도에서 촬영한 유명한 "지구돋이" 사진은 어떨까요?

어두운 우주 공간에 부분적으로 빛나는 구체가 떠 있다. 더 작고 회색인 구체가 지평선 위로 솟아오른다. 더 큰 구체에는 푸른색과 흰색 반점이 나타나 물과 구름을 암시한다. 두 구체 사이의 극명한 대비와 검은색은 솟아오르는 더 작은 구체의 연약함과 고립성을 강조한다.
쌍둥이자리(혹은 공)는 이 설명에 실패했습니다. 너무 추상적이어서 "근처 달 궤도에서 포착"이라는 문구를 추가했지만, 큰 도움이 되지 않았습니다.

멋지고 최첨단 록 앨범 커버지만, "Earthrise"와는 아무런 관련이 없습니다. 이 실험을 마무리하기 위해, 저는 지금까지 가장 잘 알려지지 않은 이미지인 에드워드 웨스턴의 산업 디자인 걸작 "Armco Steel"을 선택했습니다.

일련의 둥근 산업용 금속 탱크들이 프레임을 가득 채웁니다. 부드럽고 둥글둥글한 형태는 반복적인 패턴을 만들어냅니다. 표면에서 빛이 반사되어 곡선 형태를 더욱 강조하고 입체감을 형성합니다. 구도는 산업용 물체의 추상적인 측면에 초점을 맞추고, 기능보다는 형태와 질감을 강조합니다. 화면은 단순하고 현대적이며, 빛과 그림자가 강조됩니다.
좋은 글인 듯합니다. Dall-E가 우리 의견에 동의하는지 살펴보겠습니다.

공상과학적인 느낌은 좋지만, 원본 이미지와는 전혀 닮지 않았습니다. 실험이 참담한 실패로 끝나는 것을 원치 않았기에, 입력란 끝에 "1920년대 사진"이라는 용어를 추가하여 기계의 성능을 높이기로 했습니다.
이 특정 용어가 제가 언급했던 이미지를 설명하는 데 도움이 될 것 같았습니다. 안타깝게도 Dall-E는 또다시 저를 실망시켰고, 또 다른 프로그레시브 록 앨범 커버를 만들었습니다.

이 실험의 결과는 흥미로웠으며, 우리가 도출할 수 있는 결론은 AI 이미지 생성은 매우 예측 불가능하며, 특히 추상적인 개념일수록 더욱 그렇습니다. 입력값이 AI가 생성한 정확한 입력값이든, 사람이 생성한 불완전한 입력값이든 결과는 무작위로 나타납니다.
그러니 다음에 자신과 입력 스타일을 비난하려고 할 때는 두 장치가 서로 통신하더라도 결과가 매우 유사할 가능성이 높다는 점을 기억하세요.
댓글이 닫혔습니다.