

OpenAI o1이나 DeepSeek-R1과 같은 추론 모델은 지나치게 생각하는 데 문제가 있습니다. "1+1은 뭐지?"와 같은 간단한 질문을 하면 몇 초 동안 생각한 후 대답합니다.

이상적으로는 AI 모델도 인간과 마찬가지로 언제 직접적인 답변을 제공해야 할지, 언제 추가적인 시간과 리소스를 할당하여 응답하기 전에 생각해야 할지 판단할 수 있어야 합니다. 새로운 기술 연구자들이 제시한 메타 AI و시카고 일리노이 대학교 쿼리의 난이도에 따라 추론 예산을 할당하도록 모델을 훈련하면 응답 속도가 빨라지고 비용이 절감되며 컴퓨팅 리소스가 더 효율적으로 할당됩니다.
값비싼 추론
대규모 언어 모델(LLM)은 종종 "사고의 사슬"(CoT)이라고 알려진 더 긴 추론 사슬을 생성함으로써 추론 작업의 성능을 향상시킬 수 있습니다. CoT 기법의 성공은 모델이 문제에 대해 더 깊이 "생각"하고, 여러 답을 생성 및 검토하고, 가장 적절한 답을 선택하도록 하는 일련의 추론 시간 스케일링 기법으로 이어졌습니다.
다수결 투표(MV)는 추론 모델에서 사용되는 핵심 방법으로, 여러 개의 답을 생성하고 가장 자주 묻는 답을 선택하는 방식입니다. 이 방식의 문제점은 모델이 획일적인 행동을 취한다는 것입니다. 즉, 각 입력을 까다로운 추론 문제로 취급하고 여러 답을 생성하는 데 불필요한 리소스를 소모한다는 것입니다.
똑똑한 추론
새로운 연구 논문은 추론 모델의 응답 효율을 높이는 일련의 훈련 기법을 제안합니다. 첫 번째 단계는 "순차 투표"(SV)로, 특정 답변이 일정 횟수 이상 나타나면 모델이 추론 과정을 중단합니다. 예를 들어, 모델은 최대 8개의 답변을 생성하고 최소 3번 이상 나타나는 답변을 선택하도록 요청받습니다. 위에서 언급한 간단한 쿼리가 모델에 주어지면, 처음 세 개의 답변이 유사할 가능성이 높아 조기에 중단되어 시간과 컴퓨팅 리소스를 절약할 수 있습니다.
그들의 실험 결과, SV는 동일한 개수의 답을 생성할 때 수학 경시대회 문제에서 기존 MV보다 우수한 성능을 보였습니다. 그러나 SV는 추가적인 명령어와 코드 생성을 필요로 하기 때문에 코드 대 정확도 비율 측면에서 MV와 동등합니다.
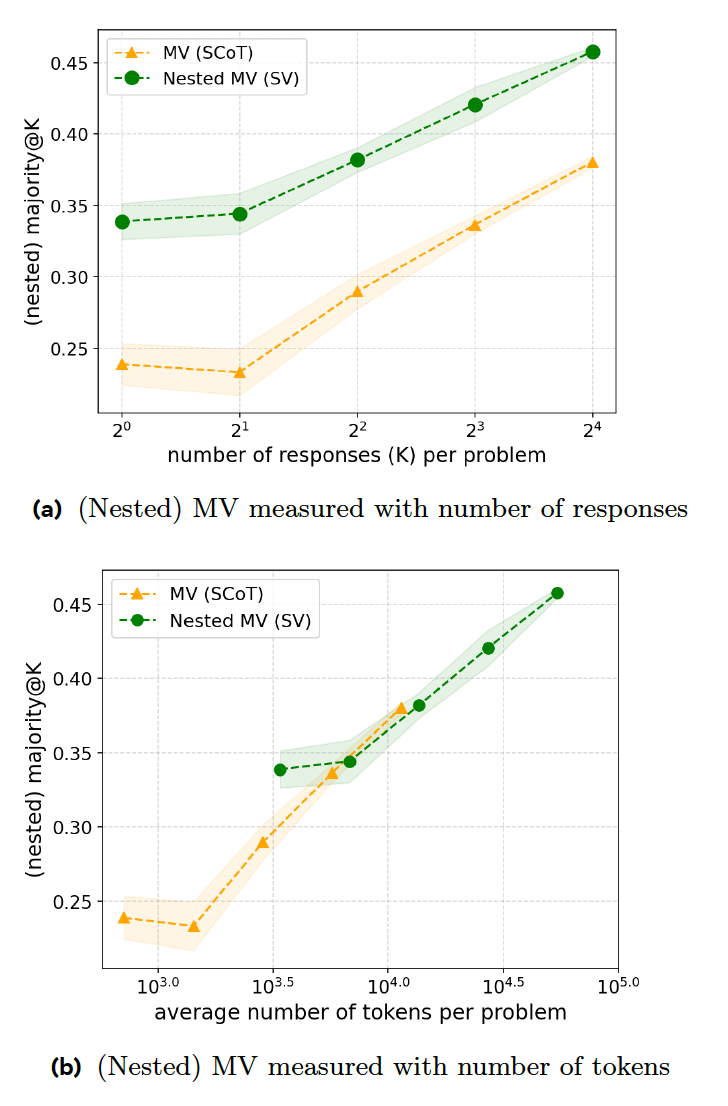
두 번째 기법인 적응형 순차 투표(ASV)는 모델이 문제를 검토하고 문제가 어려울 때만 여러 답을 생성하도록 요구함으로써 SV를 개선합니다. 1+1 청구와 같은 간단한 문제의 경우, 모델은 투표 과정을 거치지 않고 단일 답을 생성합니다. 이를 통해 모델은 간단한 문제와 복잡한 문제 모두에서 더욱 효율적으로 처리할 수 있습니다.
강화 학습
SV와 ASV 기법 모두 모델 효율성을 향상시키지만, 상당한 양의 수동 레이블링 데이터가 필요합니다. 이 문제를 완화하기 위해 연구진은 쿼리 난이도에 따라 추론 경로의 길이를 조정하도록 모델을 학습시키는 강화 학습 알고리즘인 추론 예산 제약 정책 최적화(IBPO)를 제안합니다.
IBPO는 대규모 언어 모델(LLM)이 추론 예산의 제약 내에서 응답을 개선할 수 있도록 설계되었습니다. 강화 학습 알고리즘은 ASV 궤적을 지속적으로 생성하고, 응답을 평가하고, 정답과 최적의 추론 예산을 제공하는 결과를 선택함으로써, 모델이 수동으로 레이블이 지정된 데이터로 학습했을 때 얻는 이점을 능가할 수 있도록 합니다.
실험 결과, IBPO가 파레토 전선을 개선하는 것으로 나타났습니다. 즉, 고정된 추론 예산의 경우 IBPO로 학습된 모델이 다른 기준선보다 우수한 성능을 보인다는 의미입니다.
이러한 결과는 현재 AI 모델이 어려움을 겪고 있다는 연구자들의 경고 속에서 나온 것입니다. 기업들은 고품질 학습 데이터를 확보하는 데 어려움을 겪고 있으며, 모델 개선을 위한 대안을 모색하고 있습니다.
유망한 해결책 중 하나는 강화 학습입니다. 강화 학습에서는 모델에 목표가 주어지고 스스로 해결책을 찾게 되는데, 이는 모델을 손으로 레이블이 지정된 예제를 통해 훈련시키는 지도 미세 조정(SFT)과 대조됩니다.
놀랍게도 이 모델은 인간이 미처 생각하지 못했던 해결책을 종종 찾아내곤 합니다. 이 공식은 미국 AI 연구실의 독주에 도전했던 DeepSeek-R1에서도 효과가 있었던 것으로 보입니다.
연구진은 "프롬프트 기반 방법과 SFT는 절대적인 최적화와 효율성을 확보하는 데 어려움을 겪고 있으며, 이는 SFT만으로는 자가 교정 기능을 구현할 수 없다는 추측을 뒷받침한다"고 지적합니다. 이러한 관찰 결과는 동시 연구 결과에서도 뒷받침되는데, 이는 이러한 자가 교정 행동이 프롬프트나 SFT에 의해 수동으로 생성되는 것이 아니라 학습 과정에서 자발적으로 나타난다는 것을 시사합니다.
댓글이 닫혔습니다.