

Ollama와 OpenAI의 simple-evals를 사용하여 GPQA에서 DeepSeek-R1 증류 모델의 성능 평가
로컬로 추출된 DeepSeek-R1 모델에 GPQA-Diamond 벤치마크를 설정하고 실행하여 추론 기능을 평가합니다.
최신 모델 출시 DeepSeek-R1 이 기술은 전 세계 AI 커뮤니티에서 널리 활용되고 있습니다. Meta와 OpenAI의 추론 모델에 필적하는 획기적인 성과를 달성했으며, 그 시간도 훨씬 짧고 비용도 훨씬 저렴했습니다.
하지만 기사 헤드라인과 온라인 과대광고를 넘어, 공인된 벤치마크를 사용하여 모델의 추론 능력을 어떻게 평가할 수 있을까요? 이는 AI 전문가들에게 중요한 질문입니다.
의 사용자 인터페이스 딥시크 이러한 기능을 쉽게 탐색할 수 있지만, 프로그래밍 방식으로 사용하면 더욱 심층적인 통찰력을 얻고 실제 애플리케이션에 더욱 원활하게 통합할 수 있습니다. 이러한 모델이 로컬에서 어떻게 작동하는지 이해하면 제어 및 오프라인 액세스도 향상됩니다.

이 기사에서는 사용 방법을 살펴보겠습니다. 올라마 그리고 OpenAI의 simple-evals 벤치마크를 기반으로 DeepSeek-R1 증류 모델의 추론 기능을 평가하려면 GPQA-다이아몬드 유명합니다. 이 기준은 논리적 추론 분야에서 AI 모델을 평가하는 가장 중요한 도구 중 하나로 간주됩니다.
당신에게 GitHub 저장소 링크 이 기사와 함께.
(1) 추론의 모델은 무엇인가?
DeepSeek-R1 및 OpenAI의 o-시리즈 모델(예: o1, o3)과 같은 추론 모델은 강화 학습을 통해 추론을 수행하는 대규모 언어 모델(LLM)입니다. 이러한 모델은 인공지능 분야의 최첨단 도구로서, 기계의 추론 능력과 복잡한 문제 해결 능력의 정점을 보여줍니다.
추론 모델은 반응하기 전에 심도 있는 사고를 하고, 반응하기 전에 긴 일련의 내적 사고를 생성하는 것이 특징입니다. 복잡한 문제 해결, 프로그래밍, 과학적 추론, 그리고 에이전트 워크플로의 다단계 계획에 탁월합니다. 이러한 기능 덕분에 추론 모델은 고급 소프트웨어 개발, 과학 연구, 복잡한 프로세스 자동화와 같은 분야에서 필수적인 역할을 합니다.
(2) DeepSeek-R1 모델은 무엇인가요?
DeepSeek-R1은 특별히 설계된 최첨단 오픈 소스 대규모 언어 모델(LLM)입니다. 고급 추론. 2025년 XNUMX월 연구논문으로 제출됨 "DeepSeek-R1: 강화 학습을 통한 대규모 언어 모델의 추론 능력 향상"DeepSeek-R1은 인공지능 분야의 선구적인 모델입니다.
이 모델은 671억 개의 매개변수를 갖는 대규모 언어 모델(LLM) 아키텍처를 기반으로 하며, 다음 경로를 기반으로 하는 광범위한 강화 학습(RL)을 사용하여 학습되었습니다.
- 증강의 두 단계는 향상된 추론 패턴을 발견하고 인간의 선호도에 맞추는 것을 목표로 합니다.
- 두 단계의 지도적 미세 조정은 모델의 추론 및 비추론 기능에 대한 시드 역할을 합니다.
예를 들어 DeepSeek은 두 가지 모델을 훈련했습니다.
- 첫 번째 모델, 딥시크-R1-제로, 강화 학습을 사용하여 학습된 추론 모델이며, 두 번째 모델을 학습하기 위한 데이터를 생성합니다. DeepSeek-R1.
- 이는 최종 결과에 따라 고품질 출력만 유지하는 추론 추적을 생성하여 달성됩니다.
- 즉, 대부분의 모델과 달리 이 학습 파이프라인의 강화 학습(RL) 예시는 사람이 큐레이션한 것이 아니라 모델 자체에서 생성된다는 것을 의미합니다.
결과적으로 이 모델은 다음과 같은 주요 모델과 유사한 성능을 달성했습니다. OpenAI의 o1 모델 수학, 프로그래밍, 복잡한 추론과 같은 작업에서.
(3) DeepSeek-R1의 증류 과정 및 증류 모델 이해
전체 모델 외에도 그들은 DeepSeek-R1을 기반으로 추출한 다양한 크기(1.5B, 7B, 8B, 14B, 32B, 70B)의 1개의 더 작은 고밀도 모델(DeepSeek-RXNUMX이라고도 함)을 오픈 소스로 공개했습니다. 쿠웬 또는 야마 기본 모델로서.
증류 이는 더 작은 모델("학생")이 이전에 훈련된 더 크고 강력한 모델("선생님")의 성능을 복제하도록 훈련되는 기술입니다.
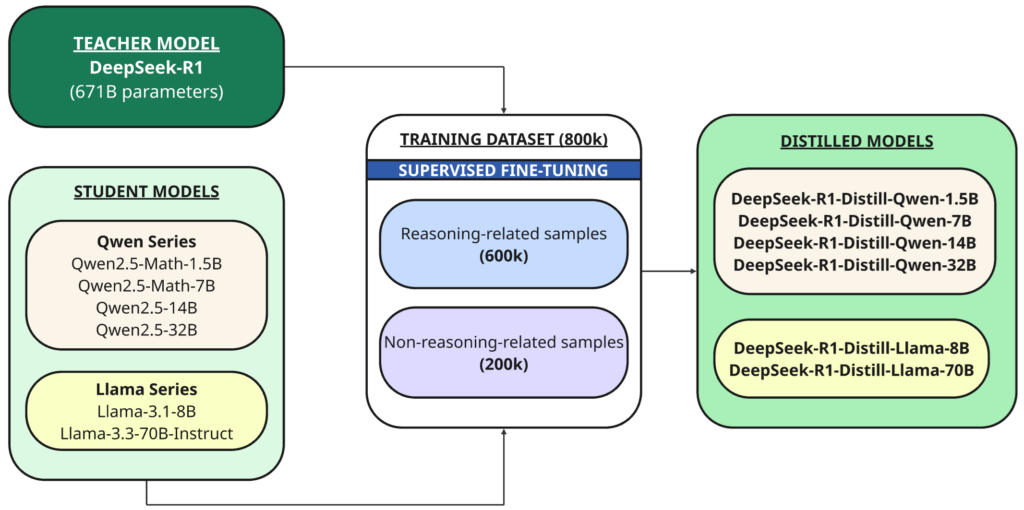
이 경우 교사는 1B DeepSeek-R671 모델이고, 학생은 이 오픈 소스 기반 모델을 사용하여 추출한 XNUMX개의 모델입니다.
DeepSeek-R1은 추론 샘플과 비추론 샘플이 혼합된 800,000개의 훈련 샘플을 생성하기 위한 교사 모델로 사용되었습니다. 감독 하에 미세 조정 기본 모델(1.5B, 7B, 8B, 14B, 32B, 70B)의 경우.
그렇다면 처음에 우리는 왜 증류를 하는 걸까요?
목표는 DeepSeek-R1 671B와 같은 대형 모델의 추론 기능을 더 작고 효율적인 모델로 이전하는 것입니다. 이를 통해 더 작은 모델도 더 빠르고 리소스 효율적으로 복잡한 추론 작업을 처리할 수 있습니다.
게다가 DeepSeek-R1은 매개변수의 수가 엄청나게 많아서(671억 개) 대부분의 소비자 기기에서 실행하기 어렵습니다.
최대 통합 메모리가 128GB인 가장 강력한 MacBook Pro조차도 671억 개의 매개변수를 가진 모델을 실행하기에는 충분하지 않습니다.
따라서 정제된 모델은 제한된 계산 리소스를 가진 장치에 배포할 가능성을 열어줍니다.
달성 느림보 1억 개의 매개변수를 가진 기존 DeepSeek-R671 모델을 단 131GB로 양자화하여 용량을 80%나 줄인 놀라운 성과입니다. 그러나 131GB의 VRAM 요구 사항은 특히 리소스가 제한된 기기를 사용하는 개발자에게 여전히 큰 장벽으로 남아 있습니다. 이번 성과는 더 많은 사용자가 대규모 AI 모델을 활용할 수 있도록 하는 데 있어 중요한 진전을 의미합니다.
(4) 최적 증류모델 선정
선택할 수 있는 증류 모델이 6가지가 있으므로, 적합한 모델을 결정하는 것은 주로 현지 장비의 성능에 달려 있습니다.
최대 성능이 필요한 고성능 GPU나 CPU를 사용하는 사용자에게는 대형 DeepSeek-R1 모델(32B 이상)이 이상적입니다. 양자 671B 버전도 사용 가능합니다.
하지만 리소스가 부족하거나 (저처럼) 더 빠른 빌드 시간을 선호한다면 8B나 14B처럼 더 작은 용량의 증류된 버전이 더 나은 선택입니다. 이는 성능과 리소스 요구 사항의 균형을 맞춰줍니다.
이 프로젝트에서는 DeepSeek-R1 모델을 추출하여 사용할 것입니다. 퀸-14B이는 귀하가 겪은 하드웨어 제한에 해당합니다. 이 모델(14B)은 정확도와 속도의 훌륭한 절충안을 나타내므로 내 개발 환경에 완벽하게 맞습니다.
(5) 대규모 언어모델의 추론능력 평가기준
대규모 언어 모델(LLM)은 일반적으로 언어 이해, 코드 생성, 지시 이행, 질문 답변 등 다양한 작업에서 성과를 측정하는 표준화된 지표를 사용하여 평가됩니다. 일반적인 지표에는 다음과 같은 것들이 있습니다. MMLU, 그리고 인간평가, 그리고 MGSM이러한 측정항목은 대규모 언어 모델의 역량을 평가하는 데 필수적입니다.
대규모 언어 모델의 추론 능력을 측정하려면 피상적인 작업을 넘어 추론에 중점을 둔 더욱 까다로운 벤치마크가 필요합니다. 고급 추론 능력 평가에 중점을 둔 몇 가지 일반적인 사례는 다음과 같습니다.
(i) AIME 2024 시험: 경쟁 수학
- 준비하다 미국 초대 수학 시험(AIME) 2024 수학적 추론에서 대규모 언어 모델(LLM)의 역량을 평가하기 위한 강력한 벤치마크입니다.
- 이 시험은 경쟁 수학에서 매우 어려운 난제로, 복잡하고 여러 단계로 구성된 문제를 제시합니다. 이 시험은 대규모 언어 모델이 복잡한 문제를 이해하고, 고급 추론을 적용하며, 정확한 기호 조작을 수행하는 능력을 평가합니다. AIME는 복잡한 수학 문제 해결 능력을 평가하는 중요한 척도입니다.
(ii) Codeforces – 경쟁 코드
- 일어나 코드포스 표준 알고리즘 챌린지로 유명한 플랫폼인 Codeforces의 실제 경쟁 프로그래밍 문제를 사용하여 대규모 언어 모델(LLM)의 추론 능력을 평가합니다. Codeforces는 복잡한 문제 해결에 있어 AI 모델의 역량을 평가하는 데 있어 최고의 기준으로 여겨집니다.
- 이러한 문제들은 대규모 언어 모델(LLM)이 복잡한 명령어를 이해하고, 논리적 및 수학적 추론을 수행하고, 다단계 솔루션을 계획하고, 정확하고 효율적인 코드를 생성하는 능력을 테스트합니다. 이러한 문제를 해결하려면 알고리즘과 데이터 구조에 대한 깊은 이해뿐만 아니라 문제를 실행 가능한 코드로 변환하는 능력이 필요합니다.
(iii) GPQA 다이아몬드 - 박사 수준 과학 질문
- GPQA-Diamond는 선택된 하위 집합입니다. 가장 어려운 질문들 표준에서 GPQA(대학원 물리학 질문과 답변) 박사 수준의 고급 주제에 대한 LLM 모델의 추론 능력의 한계를 확장하기 위해 특별히 설계된 가장 광범위한 벤치마크입니다. 이 벤치마크는 AI가 복잡한 과학 개념을 이해하고 추론하는 능력에 실질적인 도전 과제를 제시합니다.
- GPQA에는 개념적이고 계산 기반의 대학원 질문이 포함되어 있는 반면, GPQA-Diamond는 가장 어려운 질문과 집중적인 추론이 필요한 질문만 분리했습니다.
- 이 기준은 "구글에 취약한" 것으로 간주되는데, 이는 제한 없는 웹 접근 환경에서도 답하기 어렵다는 것을 의미합니다. 따라서 대규모 언어 모델의 독립적인 추론 능력을 평가하는 데 유용한 도구입니다.
- 다음은 GPQA-Diamond 문제의 예입니다.
### GPQA 다이아몬드 - 예시 문제 (분자생물학) 진핵세포는 거대분자 구성 요소를 에너지로 전환하는 메커니즘을 진화시켰습니다. 이 과정은 세포의 에너지 공장인 미토콘드리아에서 일어납니다. 일련의 산화환원 반응을 통해 음식에서 얻은 에너지는 인산기 사이에 저장되어 세포 내에서 보편적인 화폐로 사용됩니다. 에너지를 실은 분자들은 미토콘드리아에서 방출되어 모든 세포 과정에 관여합니다. 새로운 항당뇨제를 발견했고, 이 약물이 미토콘드리아에 미치는 영향을 조사하고자 합니다. HEK293 세포주를 사용하여 다양한 실험을 계획했습니다. 아래 나열된 실험 중 어떤 것이 귀하의 약물의 미토콘드리아 역할을 발견하는 데 도움이 되지 않습니까? (A) 포도당 흡수 비색 검정 키트에 따른 미토콘드리아의 차등 원심 분리 추출 (B) 2.5 µM 5,5',6,6'-테트라클로로-1,1',3,3'-테트라에틸벤즈이미다졸릴카르보시아닌 요오드로 표지한 후 유세포 분석 (C) 재조합 루시페라제로 세포를 형질 전환하고 상층액에 5 µM 루시페린을 첨가한 후 루미노미터 판독 (D) 세포의 미토-RTP 염색 후 공초점 형광 현미경 검사
이 프로젝트에서는 우리는 GPQA-Diamond를 결론의 기준으로 사용합니다.내가 사용했듯이 OpenAI 그리고 DeepSeek 추론 모델을 평가하기 위해 GPQA-Diamond를 평가 기준으로 선택한 것은 인공지능 개발 분야에서 그 복잡성과 중요성을 입증합니다.
(6) 사용 도구
이 프로젝트에서는 주로 다음을 사용합니다. 올라마 그리고 단순 평가 OpenAI에서 제공하는 Ollama는 대규모 언어 모델을 로컬에서 실행할 수 있는 강력한 플랫폼이며, simple-evals는 이러한 모델의 성능을 평가할 수 있는 프레임워크를 제공합니다.
(i) 올라마
올라마 Olama는 컴퓨터나 로컬 서버에서 대규모 언어 모델(LLM)을 실행하는 것을 간소화하는 오픈소스 도구입니다. Olama는 AI 모델을 로컬에서 실행하기에 이상적인 플랫폼입니다.
Olama는 관리자이자 런타임 역할을 하며 다운로드 및 환경 설정과 같은 작업을 처리합니다. 이를 통해 사용자는 지속적인 인터넷 연결이나 클라우드 서비스 의존 없이도 이러한 모델과 상호 작용할 수 있습니다. 로컬 대규모 언어 모델(LLM) 관리는 Olama의 핵심 기능입니다.
DeepSeek-R1을 포함한 다양한 대규모 오픈소스 언어 모델을 지원하며 macOS, Windows, Linux와 크로스 플랫폼 호환됩니다. 또한, 간편한 설정과 효율적인 리소스 활용을 제공합니다. Ollama를 사용하면 기기에서 바로 AI의 힘을 활용할 수 있습니다.
중대한로컬 컴퓨터에 다음이 있는지 확인하세요. GPU 접근성 Ollama의 경우, 이렇게 하면 성능이 크게 향상되고 후속 벤치마킹이 CPU보다 더 효율적이 됩니다. 명령을 실행하세요.
nvidia-smi터미널에서 GPU가 감지되는지 확인하세요. 이를 통해 기기의 성능이 극대화되어 모델을 효율적으로 실행할 수 있습니다.
(ii) 언어 모델을 평가하기 위한 OpenAI simple-evals 라이브러리
준비 단순 평가 제로샷 평가 방법론과 사고 연쇄 프롬프팅을 사용하여 언어 모델을 평가하도록 설계된 경량 라이브러리입니다. MMLU, MATH, GPQA, MGSM, HumanEval과 같은 널리 사용되는 평가 벤치마크를 통합하고, 실제 사용 사례를 시뮬레이션하여 복잡한 추론 작업에서 AI 모델의 성능을 평가하는 것을 목표로 합니다.
여러분 중 일부는 OpenAI의 가장 인기 있고 포괄적인 평가 라이브러리인 OpenAI에 대해 잘 알고 있을 것입니다. 평가이는 simple-evals와 다릅니다.
실제로, 페이지는 다음을 나타냅니다. README simple-evals 사양은 라이브러리를 대체하려는 것이 아님을 나타냅니다. 평가.
그렇다면, 왜 simple-evals를 사용할까요?
간단한 대답은 다음과 같습니다. 단순 평가 우리가 목표로 하는 추론 표준(예: GPQA)에 대한 평가 텍스트가 내장되어 있는데, 라이브러리에는 그런 기능이 없습니다. 평가.
게다가, 저는 simple-evals 외에 해당 언어에서 직접적이고 기본적인 방식을 제공하는 다른 도구나 플랫폼을 찾지 못했습니다. Python 특히 Ollama와 협력할 때 GPQA와 같은 여러 주요 표준을 실행합니다.
(7) 평가 결과
평가의 일환으로 다음을 선택했습니다. 20개의 무작위 질문 GPQA-Diamond 문제 세트에서 198개의 질문을 다루세요. 14B 양식 증류기총 216분이 걸렸는데, 질문당 약 11분 정도였습니다.
결과는 기록된 대로 다소 실망스러웠습니다. 10% 단, 73.3B DeepSeek-R1 모델에서 보고된 결과인 671%보다 상당히 낮습니다.
내가 알아차린 주요 문제는 집중적인 내부 추론 중에 이 모델은 종종 아무런 답변도 생성하지 못하거나(예: 출력의 최종 줄로 추론 코드를 반환) 예상되는 객관식 형식에 맞지 않는 응답을 제공했습니다(예: 답변: A).
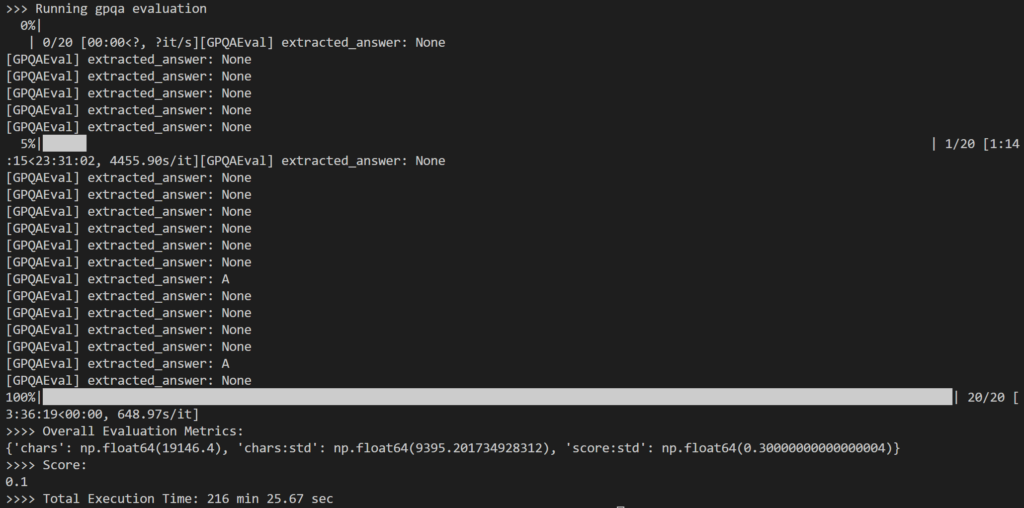
위에 표시된 대로 많은 출력이 다음과 같이 끝났습니다. None simple-evals의 정규식 논리가 LLM 응답에서 예상되는 답변 패턴을 감지할 수 없기 때문입니다.
그 동안 인간과 같은 추론 질문에 대한 답변의 정확도 측면에서 더 나은 성과를 기대했기 때문에 관찰하는 것이 흥미로웠습니다.
온라인 사용자들이 더 큰 32B 모델조차 o1만큼 성능이 좋지 않다고 언급하는 것을 본 적도 있습니다. 이는 증류 추론 모델의 유용성에 대한 의문을 제기했는데, 특히 긴 추론을 생성했음에도 불구하고 정답을 도출하는 데 어려움을 겪고 있기 때문입니다.
하지만 GPQA-Diamond는 매우 까다로운 벤치마크이므로 이러한 모델은 더 간단한 추론 작업에도 유용할 수 있습니다. 또한, 연산 요구 사항이 낮아 구현이 더 쉽습니다.
게다가 DeepSeek 팀은 벤치마킹 과정의 일환으로 여러 테스트를 실행하고 결과를 평균화할 것을 권장했는데, 저는 시간 제약으로 인해 이를 간과했습니다.
(8) 자세한 단계별 가이드
지금까지 우리는 기본 개념과 주요 결론을 다루었습니다.
직접 기술적인 경험을 해보고 싶으시다면 이 섹션에서 내부 메커니즘과 단계별 구현 과정을 자세히 살펴보세요. 이 실용적인 기술 가이드를 통해 시스템 작동 방식을 포괄적으로 이해할 수 있습니다.
보기(또는 복사) 동반 GitHub 저장소 가상 환경을 설정하는 데 필요한 요구 사항은 다음과 같습니다. 여기.
(i) 초기 설정 – Ollama
Ollama를 다운로드하는 것부터 시작하겠습니다. 방문하세요
올라마 다운로드 페이지, 운영 체제를 선택하고 해당 설치 지침을 따르세요.
설치가 완료되면 Ollama 애플리케이션(Windows 및 macOS용)을 두 번 클릭하거나 명령을 실행하여 Ollama를 시작합니다. ollama serve 터미널에서.
(ii) 초기 설정 – OpenAI simple-evals
simple-evals 설정은 비교적 독특합니다.
simple-evals는 라이브러리로 표현되지만 파일이 없습니다 __init__.py 저장소에 있다는 것은 적절한 Python 패키지로 구성되지 않았다는 것을 의미합니다.이로 인해 로컬 저장소를 복제한 후 가져오기 오류가 발생합니다. 즉, 소프트웨어 엔지니어링에서 일반적으로 사용되는 표준 Python 패키지가 아닙니다.
PyPI에도 게시되지 않았고 다음과 같은 표준 패키징 파일이 없습니다. setup.py 또는 pyproject.toml를 통해 설치할 수 없습니다. pip이로 인해 새로운 개발자에게는 약간의 어려움이 따릅니다.
다행히도 우리는 사용할 수 있습니다 Git 하위 모듈 간단한 대안으로, 이러한 모듈을 사용하면 하나의 Git 저장소를 다른 저장소에 포함할 수 있으므로 종속성을 더 쉽게 관리할 수 있습니다.
"`html
Git 서브모듈을 사용하면 다른 Git 저장소의 내용을 프로젝트에 포함할 수 있습니다. 외부 저장소(예: simple-evals)에서 파일을 가져오지만, 히스토리는 별도로 보관합니다.
simple-evals의 내용을 추출하려면 두 가지 방법(A 또는 B) 중 하나를 선택할 수 있습니다.
(a) 내 프로젝트 저장소를 복제하는 경우
내 프로젝트 저장소에는 이미 다음이 포함되어 있습니다. simple-evals 하위 모듈이므로 다음을 실행하면 됩니다.
git submodule update --init --recursive(b) 새로 만든 프로젝트에 추가하는 경우.
simple-evals를 하위 모듈로 수동으로 추가하려면 다음을 실행하세요.
git submodule add https://github.com/openai/simple-evals.git simple_evals주의: 저것 simple_evals 결국 (와 함께 밑줄)는 매우 중요합니다. 폴더 이름을 지정하고 대신 하이픈을 사용합니다(예: 간단한-evals)로 인해 나중에 가져오기 문제가 발생할 수 있습니다.
마지막 단계(두 방법 모두)
저장소의 내용을 가져온 후에는 파일을 만들어야 합니다. __init__.py 폴더가 비어 있음 simple_evals 새로 생성된 파일은 모듈로 가져올 수 있습니다. 직접 생성하거나 다음 명령을 사용할 수 있습니다.
touch simple_evals/__init__.py(iii) Ollama를 통해 DeepSeek-R1 모델 가져오기
다음 단계는 다음 명령을 사용하여 선택한 로컬 증류 모델(예: 14B)을 다운로드하는 것입니다.
사용 가능한 DeepSeek-R1 모델 목록은 Ollama에서 확인할 수 있습니다. 여기최상의 성능을 위해서는 최신 버전의 템플릿을 사용하는 것이 좋습니다.
ollama pull deepseek-r1:14b(넷째) 설정 지정
아래와 같이 설정 YAML 파일에서 매개변수를 정의합니다.
# config/config.yaml MODEL_NAME: "deepseek-r1:14b" # 모델 이름(Ollama 모델 목록과 일치) MODEL_TEMPERATURE: 0.6 # DeepSeek-R1의 경우 0.5~0.7 사이로 설정 EVAL_BENCHMARK: "gpqa" GPQA_VARIANT: "diamond" EVAL_N_EXAMPLES: 20
모델 온도는 다음과 같이 설정됩니다. 0.6 (일반적인 기본값 0과 비교) 이는 DeepSeek의 사용 권장 사항을 따르며, 온도 범위는 0.5~0.7(권장 0.6)입니다. 무한 반복이나 일관성 없는 출력을 방지합니다. 이 설정은 출력 품질을 개선하고 일관성을 보장하는 데 필요합니다.
체크 아웃 할 기회를 놓치지 마세요 DeepSeek-R1의 독특하고 흥미로운 사용 권장 사항 – 특히 벤치마크의 경우 – DeepSeek-R1 모델을 사용할 때 최적의 성능을 보장합니다.
EVAL_N_EXAMPLES 이 매개변수는 평가에 사용되는 총 198개 문항 중 문항 수를 설정하는 데 사용됩니다. 이 매개변수는 사용 가능한 자원과 특정 시험 목표에 따라 평가 과정을 조정하는 데 필요합니다.
(v) 샘플러 코드 설정
simple-evals 프레임워크 내에서 Ollama 기반 언어 모델을 지원하기 위해 다음과 같은 사용자 정의 래퍼 클래스를 생성합니다. OllamaSampler 그리고 그것을 안에 보관하세요 utils/samplers/ollama_sampler.py샘플러는 언어 모델의 성능을 테스트하고 평가하는 데 필수적인 구성 요소입니다.
# utils/samplers/ollama_sampler.py ollama 클래스 OllamaSampler 가져오기: def __init__(self, model_name=None, temperature=0): self.model_name = model_name self.temperature = temperature def __call__(self, prompt_messages): prompt_text = prompt_messages[-1]["content"] response = ollama.chat(model=self.model_name, messages=[{"role": "user", "content": prompt_text}], options={"temperature": self.temperature} ) response_content = response["message"]["content"] return response_content def _pack_message(self, content, role): return {"role": role, "content": content}
이 맥락에서 그것은 다음을 의미합니다. 샘플러 (샘플러) 주어진 프롬프트를 기반으로 언어 모델에서 출력을 생성하는 Python 클래스입니다. 이 도구는 모델이 다양하고 대표적인 응답을 생성하도록 하는 데 필수적입니다.
simple-evals의 샘플러는 OpenAI나 Claude와 같은 제공자만 지원하므로 Ollama와 호환되는 인터페이스를 제공하는 샘플러 클래스가 필요합니다. 이를 통해 평가 프레임워크와의 원활한 통합이 보장됩니다.
일어나 OllamaSampler GPQA 질문 프롬프트를 추출하여 지정된 온도와 함께 모델에 제출하고 일반 텍스트 응답을 반환합니다. 온도는 출력의 무작위성을 제어하는 중요한 매개변수입니다.
포함된 방법 _pack_message 출력 형식이 simple-evals의 평가 스크립트에서 예상하는 형식과 일치하는지 확인합니다. 이를 통해 일관성과 구문 분석의 용이성이 보장됩니다.
6. 평가 스크립트 만들기
다음 코드는 파일에 평가 구현을 설정하는 방법을 보여줍니다. main.py, 카테고리 사용을 포함 GPQAEval simple-evals 라이브러리를 사용하여 GPQA 벤치마크 테스트를 실행합니다.
기능 run_eval() Ollama를 사용하여 대규모 언어 모델(LLM)을 GPQA와 같은 벤치마크와 비교 테스트하는 구성 가능한 평가 도구입니다. 이 기능은 모델 성능을 정확하게 평가하는 데 필수적입니다.
# main.py def run_eval(): start_time = time.time() # 구성 파일 로드 config = load_config("config/config.yaml") # Ollama 샘플러 초기화(Ollama 채팅을 둘러싼 래퍼) ollama_sampler = OllamaSampler(model_name=config["MODEL_NAME"], temperature=config["MODEL_TEMPERATURE"] ) # EVAL_BENCHMARK를 기반으로 사용할 평가 클래스 선택 eval_benchmark = config["EVAL_BENCHMARK"] # GPQA print(f">>> {eval_benchmark} 평가 실행") if eval_benchmark == "gpqa": eval_class = GPQAEval eval_kwargs = { "n_repeats": config["EVAL_N_REPEATS"], # 기본값 1 "num_examples": config["EVAL_N_EXAMPLES"], # 20으로 설정 "variant": config["GPQA_VARIANT"], # GPQA-Diamond 하위 집합 } else: raise ValueError( f"Unknown EVAL_BENCHMARK '{eval_benchmark}'." ) # 적절한 평가를 인스턴스화하고 실행합니다.evaluator = eval_class(**eval_kwargs) results = evaluator(ollama_sampler) # 샘플러로 평가를 실행합니다.end_time = time.time() elapsed_seconds = end_time - start_time minutes, seconds = divmod(elapsed_seconds, 60) # 총 소요 시간을 계산합니다.# 반환된 결과는 SingleEvalResult 목록과 집계된 메트릭을 포함하는 EvalResult입니다.print(">>>> 전체 평가 메트릭:", results.metrics) print(">>>> 점수:", results.score) print(f">>>> 총 실행 시간: {int(minutes)} min {seconds:.2f} sec") if __name__ == "__main__": # GPQA 평가 실행 run_eval()
이 함수는 구성 파일에서 설정을 로드하고, simple-evals에서 적절한 평가 클래스를 설정하고, 모델을 균일한 평가 프로세스로 실행합니다. 이 함수는 파일에 저장됩니다. main.py명령을 사용하여 실행할 수 있습니다. python main.py이를 통해 일관되고 반복 가능한 평가 프로세스가 보장됩니다.
위 단계를 따라 증류된 DeepSeek-R1 모델에 GPQA-Diamond 벤치마크를 성공적으로 설정하고 실행했습니다. 이 과정을 통해 모델의 성능에 대한 귀중한 통찰력을 얻을 수 있습니다.
결론
이 기사에서는 DeepSeek-R1에서 추출한 모델을 탐색하고 평가하기 위해 Ollama 및 OpenAI의 simple-evals와 같은 도구를 결합하는 방법을 살펴봅니다. 대규모 언어 모델의 성능 평가.
증류된 모델은 GPQA-Diamond와 같은 까다로운 추론 벤치마크에서 671억 개의 매개변수를 가진 원래 모델과 아직 비교하기 어려울 수 있습니다. 그러나 증류를 통해 대규모 언어 모델(LLM)의 추론 기능 범위를 어떻게 확장할 수 있는지 보여줍니다. 대규모 언어 모델에 대한 접근성 개선 이는 이 분야의 주요 목표입니다.
복잡한 박사급 작업에서는 성능이 낮더라도, 이러한 소규모 변형은 덜 까다로운 시나리오에서는 여전히 적용 가능하여 더 광범위한 장치에 효율적인 로컬 배포를 가능하게 할 수 있습니다. 이는 대규모 언어 모델을 로컬로 배포 바크파라.
댓글이 닫혔습니다.