

지능형 의사결정 회로를 사용하여 대규모 언어 모델(LLM)에서 확실성 달성
기술 분야에서 불확실성은 새로운 것이 아닙니다. 모든 현대 시스템은 수학적으로 입증된 제어 구조를 사용하여 불확실한 입력과 출력을 극복합니다.
AI 에이전트의 가능성은 세상을 휩쓸고 있습니다. 에이전트는 주변 세상과 상호 작용하고, 기사를 작성하고(하지만 이 기사는 아닙니다), 사용자를 대신하여 작업을 수행하며, 모든 작업 자동화의 어려운 부분을 쉽고 편리하게 만들어 줍니다.
상담원은 프로세스에서 가장 어려운 부분을 집중적으로 처리하고 문제를 신속하게 해결합니다. 때로는 너무 빠르게 처리하기도 합니다. 상담원 기반 프로세스에서 결과 결정을 위해 사람이 직접 참여해야 하는 경우, 사람의 검토 단계가 프로세스의 병목 현상이 될 수 있습니다.
상담원 의존 프로세스의 예로는 고객 전화 통화를 처리하고 분류하는 것이 있습니다. 99.95%의 정확도를 가진 상담원이라도 5건의 전화를 듣는 동안 10,000번의 오류를 범합니다. 이 사실을 알고 있음에도 불구하고, 상담원은 당신에게 그 오류를 알려줄 수 없습니다. 어느 5건의 통화 중 10,000건이 잘못 분류되었습니다.

"LLM-as-a-Judge" 기법은 각 입력을 다른 LLM 프로세스에 입력하여 입력에서 나오는 출력이 정확한지 평가하는 기법입니다. 하지만 이는 또 다른 LLM 프로세스이기 때문에 부정확할 수도 있습니다. 이 두 가지 확률적 프로세스는 참 양성, 거짓 음성, 참 음성, 거짓 양성으로 구성된 혼동 행렬을 생성합니다.
즉, LLM 프로세스에서 올바르게 분류된 항목이 LLM 심사위원에 의해 잘못된 것으로 판단될 수 있으며, 그 반대의 경우도 마찬가지입니다.
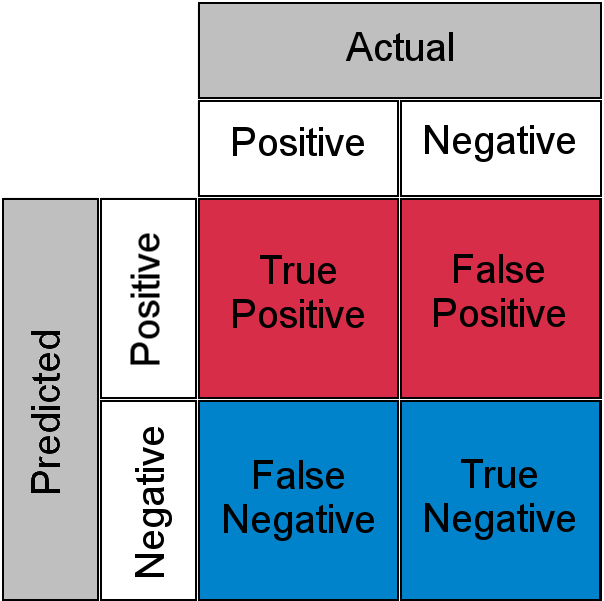
이 때문에 " 알려지지 않은 알려진 것 민감한 업무의 경우, 사람이 10,000만 건의 통화를 모두 검토하고 이해해야 합니다. 다시 같은 병목 현상에 직면하게 되는 거죠.
에이전트 기반 프로세스에 통계적 확실성을 어떻게 더 높일 수 있을까요? 이 글에서는 에이전트 기반 프로세스의 확실성을 높이고, 이를 임의의 수의 에이전트로 일반화하며, 향후 시스템 투자를 유도하는 데 도움이 되는 비용 함수를 개발하는 시스템을 구축합니다. 이 글에서 사용하는 코드는 제 저장소에서 확인할 수 있습니다. AI 결정 회로.
AI 의사결정 회로
오류 감지 및 수정은 새로운 개념이 아닙니다. 오류 수정은 디지털 및 아날로그 전자공학 분야에서 매우 중요합니다. 양자 컴퓨팅의 발전조차도 오류 수정 및 감지 기능의 확장에 의존합니다. 우리는 이러한 시스템에서 영감을 얻어 인공지능 에이전트에 유사한 기능을 구현할 수 있습니다. 예를 들어, 인공지능 알고리즘 통신 시스템에서 발견되는 오류 정정 기술을 고도로 활용합니다.
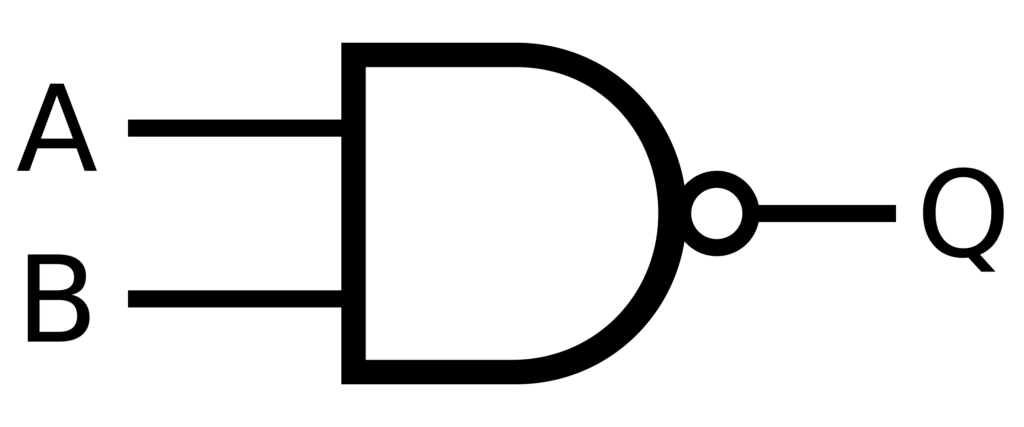
부울 논리에서 NAND 게이트는 모든 연산을 수행할 수 있기 때문에 계산의 성배와 같습니다. NAND 게이트는 기능적으로 완전하며, 이는 NAND 게이트만으로 모든 논리 연산을 생성할 수 있음을 의미합니다. 이 원리는 인공지능 시스템에 적용되어 오류 정정 기능이 내장된 강력한 의사 결정 구조를 생성할 수 있습니다. 이를 통해 다음과 같은 작업을 수행할 수 있습니다. 신경망 더욱 안정적이며 불완전하거나 노이즈가 있는 데이터를 처리할 수 있습니다.
전자 회로부터 지능형 의사결정(AI) 회로까지
전자 회로가 반복과 검증을 통해 신뢰할 수 있는 계산을 보장하는 것처럼, 지능형 의사 결정(AI) 회로는 서로 다른 관점을 가진 여러 에이전트를 활용하여 더욱 정확한 결과를 도출할 수 있습니다. 이러한 회로는 정보 이론과 부울 논리의 원리를 사용하여 구축할 수 있습니다.
- 중복 처리: 여러 AI 에이전트가 동일한 입력을 독립적으로 처리하는데, 이는 최신 CPU가 중복 회로를 사용하여 하드웨어 오류를 감지하는 방식과 유사합니다. 이러한 프로세스는 AI 시스템의 안정성을 향상시킵니다.
- 합의 메커니즘: 의사 결정 결과는 결함 허용 전자 장치의 다수결 논리 게이트와 유사한 투표 시스템이나 가중 평균을 사용하여 결합됩니다. 이러한 메커니즘은 최종 결정이 에이전트의 합의를 반영하도록 보장합니다.
- 검증 에이전트: 전문 AI 감사원은 오류 감지 코드와 유사하게 작동하여 출력의 합리성을 확인합니다. 패리티 비트 또는 순환 중복 검사(CRC 검사)이러한 에이전트는 잘못된 결정을 내릴 가능성을 줄여줍니다.
- 인간 참여형 통합: 생체 인식 시스템이 최종 검증 단계로 인간의 감독을 사용하는 것과 유사하게, 의사결정 과정의 주요 지점에서 전략적 인간 검증을 실시함으로써 중요한 결정이 인간의 평가를 거치도록 보장합니다.
인공지능 의사결정 회로의 수학적 기초
이러한 시스템의 신뢰성은 확률 이론을 사용하여 정량적으로 결정될 수 있습니다.
한 가지 요인의 경우 실패 확률은 테스트 데이터 세트에 저장된 시간 경과에 따른 관찰된 정확도에서 비롯됩니다. 랭스미스.

90%의 정확도를 갖는 요인의 경우 실패 확률은 p_1، 1–0.9 0.1 즉 10%입니다.

동일한 입력에 대해 두 개의 독립적인 요인이 실패할 확률은 두 요인이 모두 정확할 확률을 곱한 값입니다.
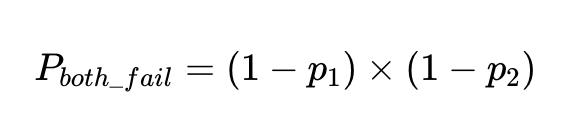
이러한 클라이언트에 대해 N번의 실행이 있는 경우 총 실패 수는 다음과 같습니다.
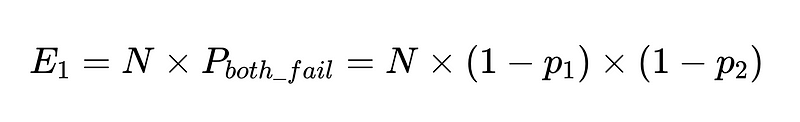
따라서 두 명의 독립적인 작업자가 10,000%의 정확도로 90번을 실행하면 실패할 것으로 예상되는 숫자는 100입니다.
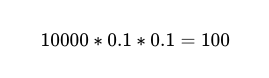
하지만 아직은 알 수 없습니다. 어느 10,000건의 전화 통화 중 100건은 실제로 실패한 통화입니다.
우리는 이 아이디어의 네 가지 확장을 결합하여 주어진 응답에 대한 확신을 제공하는 더욱 강력한 솔루션을 제공할 수 있습니다.
- 기본 분류기(위의 단순 해상도)
- 백업(위의 간단한 해결 방법)
- 스키마 검사기(예: 0.7 해상도)

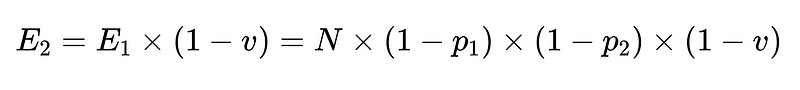
- 마지막으로, 부정적인 검증자(예: n = 정확도 0.6)
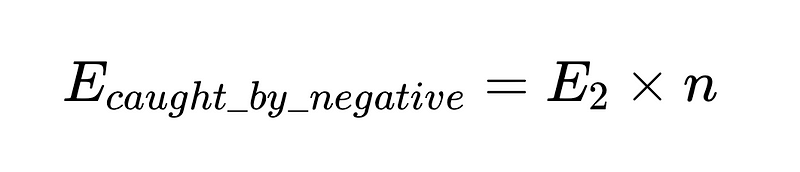
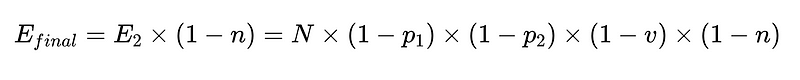
이것을 코드로 표현하려면 (완전한 창고), 우리는 사용할 수 있습니다 Python 기초적인:
def primary_parser(self, customer_input: str) -> Dict[str, str]:
"""
Primary parser: Direct command with format expectations.
"""
prompt = f"""
Extract the category of the customer service call from the following text as a JSON object with key 'call_type'.
The call type must be one of: {', '.join(self.call_types)}.
If the category cannot be determined, return {{'call_type': null}}.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def backup_parser(self, customer_input: str) -> Dict[str, str]:
"""
Backup parser: Chain of thought approach with formatting instructions.
"""
prompt = f"""
First, identify the main issue or concern in the customer's message.
Then, match it to one of the following categories: {', '.join(self.call_types)}.
Think through each category and determine which one best fits the customer's issue.
Return your answer as a JSON object with key 'call_type'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
try:
# Try to parse the response as JSON
result = json.loads(response.content.strip())
return result
except json.JSONDecodeError:
# If JSON parsing fails, try to extract the call type from the text
for call_type in self.call_types:
if call_type in response.content:
return {"call_type": call_type}
return {"call_type": None}
def negative_checker(self, customer_input: str) -> str:
"""
Negative checker: Determines if the text contains enough information to categorize.
"""
prompt = f"""
Does this customer service call contain enough information to categorize it into one of these types:
{', '.join(self.call_types)}?
Answer only 'yes' or 'no'.
Customer input: "{customer_input}"
"""
response = self.model.invoke(prompt)
answer = response.content.strip().lower()
if "yes" in answer:
return "yes"
elif "no" in answer:
return "no"
else:
# Default to yes if the answer is unclear
return "yes"
@staticmethod
def validate_call_type(parsed_output: Dict[str, Any]) -> bool:
"""
Schema validator: Checks if the output matches the expected schema.
"""
# Check if output matches expected schema
if not isinstance(parsed_output, dict) or 'call_type' not in parsed_output:
return False
# Verify the extracted call type is in our list of known types or null
call_type = parsed_output['call_type']
return call_type is None or call_type in CALL_TYPES이러한 작업을 논리와 결합하면, 부울 간단히 말해서, 우리는 각 답변에 대해 비슷한 정확도와 신뢰도를 얻을 수 있습니다.
def combine_results(
primary_result: Dict[str, str],
backup_result: Dict[str, str],
negative_check: str,
validation_result: bool,
customer_input: str
) -> Dict[str, str]:
"""
Combiner: Combines the results from different strategies.
"""
# If validation failed, use backup
if not validation_result:
if RobustCallClassifier.validate_call_type(backup_result):
return backup_result
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If negative check says no call type can be determined but we extracted one, double-check
if negative_check == 'no' and primary_result['call_type'] is not None:
if backup_result['call_type'] is None:
return {'call_type': None, "confidence": "low", "needs_human": True}
elif backup_result['call_type'] == primary_result['call_type']:
# Both agree despite negative check, so go with it but mark low confidence
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {"call_type": None, "confidence": "low", "needs_human": True}
# If primary and backup agree, high confidence
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "high"}
# Default: use primary result with medium confidence
if primary_result['call_type'] is not None:
return {'call_type': primary_result['call_type'], "confidence": "medium"}
else:
return {'call_type': None, "confidence": "low", "needs_human": True}
의사결정 논리: 단계별 설명
1단계: 품질 관리 시스템이 실패하는 경우
if not validation_result:즉, "품질 관리 전문가(감사자)가 초기 분석을 거부하면 신뢰하지 마십시오."라는 의미입니다. 그러면 시스템은 백업 의견을 대신 사용하려고 시도합니다. 이마저도 검증에 실패하면 해당 사례를 인간 전문가의 검토 대상으로 표시합니다. 이러한 조치를 통해 부정확한 데이터에 의존하지 않도록 합니다.
간단히 말해서, "첫 번째 답변에 문제가 있으면 대체 방법을 시도해 보겠습니다. 그래도 문제가 있다면 전문가에게 문의해 보세요." 이렇게 하면 복잡한 문제도 올바르게 처리할 수 있습니다.
2단계: 불일치 사항 해결
if negative_check == 'no' and primary_result['call_type'] is not None:이 단계에서는 특정 유형의 불일치를 확인합니다. "수동성 검사기에서는 호출 유형이 없어야 하지만 기본 분석가에서는 유형을 찾았습니다."
이런 경우, 시스템은 폴백 분석가의 도움에 따라 손익분기점을 찾습니다.
- 백업 분석가가 통화 유형이 없다고 동의하면 해당 통화는 인적 요소로 전송됩니다.
- 백업 분석가가 기본 분석가와 동의하는 경우 ← 수락이 이루어졌지만 신뢰도는 중간 수준입니다.
- 백업 분석가가 다른 통화 유형을 가지고 있는 경우 ← 이는 인적 요소로 전송됩니다.
이는 "한 전문가가 '분류 불가'라고 말하고 다른 전문가가 '분류 불가'라고 말하면, 동점자 판정을 내리는 사람이 필요하다"는 말과 유사합니다. 이러한 메커니즘은 통화 유형을 정확하게 분류하고 잠재적 오류를 줄이는 데 필수적입니다.
3단계: 전문가들이 동의할 때
if primary_result['call_type'] == backup_result['call_type'] and primary_result['call_type'] is not None:주 분석가와 백업 분석가가 독립적으로 동일한 결론에 도달하면 시스템은 "높은 신뢰도" 라벨을 부여합니다. 이는 최상의 시나리오이며, 여러 분석 결과가 최종적으로 일치할 때 이러한 이상적인 상황이 발생합니다.
간단히 말해서, "두 전문가가 서로 다른 방법을 사용하여 독립적으로 동일한 결론에 도달했다면, 우리는 그들의 결론이 옳다고 상당히 확신할 수 있습니다." 이는 전문가 합의를 나타내며, 정확성과 신뢰성을 나타내는 강력한 지표입니다.
4단계: 기본 처리
특별 조건이 적용되지 않는 경우, 시스템은 주 분석가의 결과를 "중간" 신뢰도로 기본 설정합니다. 주 분석가가 통화 유형을 판단할 수 없는 경우, 전문 분석가의 검토를 위해 해당 사례를 표시합니다.
오류를 줄이는 데 있어 이 접근 방식의 중요성
이 논리는 다음과 같은 방법으로 강력한 시스템을 구축하는 데 기여합니다.
- 거짓 양성 감소이 시스템은 여러 방법이 일치할 때만 높은 신뢰도를 제공하며, 이로 인해 잘못된 경보가 크게 줄어듭니다.
- 모순을 발견하다시스템의 여러 부분이 다르면 신뢰도가 떨어지거나 문제가 인간 검토자에게 보고되어 잠재적인 문제가 간과되지 않도록 보장됩니다.
- 스마트 에스컬레이션인간 검토자는 자신의 전문성이 정말 필요한 사례만 검토하여 검토 프로세스의 효율성을 높이고 인적 자원의 스트레스를 줄입니다.
- 신탁 지정결과에는 시스템의 신뢰 수준이 포함되어 있어 후속 프로세스에서 높은 신뢰도와 중간 신뢰도 결과를 다르게 처리할 수 있으며, 이는 정보에 입각한 의사 결정을 내리는 데 중요합니다.
이러한 접근 방식은 전자 기기가 중복 회로와 투표 메커니즘을 사용하여 오류로 인한 시스템 장애를 방지하는 방식과 유사합니다. AI 시스템에서 이러한 유형의 신중한 조합 논리는 인간 검토자가 가장 큰 가치를 창출하는 부분에만 효율적으로 투입하는 동시에 오류율을 크게 줄일 수 있습니다. 이를 통해 리소스 최적화와 오류 감소가 모두 보장되어 더욱 안정적이고 정확한 시스템을 구축할 수 있습니다.
예
2015년 필라델피아 수도국은 다음을 발표했습니다. 카테고리별 고객 통화 통계. 고객 통화를 파악하는 것은 상담원이 처리하는 매우 일반적인 프로세스입니다. 모든 고객 통화를 사람이 직접 듣는 대신, 상담원은 훨씬 더 빠르게 통화를 듣고 정보를 추출하여 추가 데이터 분석을 위해 분류할 수 있습니다. 수자원 관리에 있어 이러한 방식은 중요한데, 중요한 문제를 더 빨리 파악할수록 더 빨리 해결할 수 있기 때문입니다.
실험을 하나 해 보겠습니다. 저는 대규모 언어 모델(LLM)을 사용하여 문제의 전화 통화에 대한 가짜 녹취록을 생성했습니다. "다음 범주가 주어졌을 때, 해당 전화 통화의 간략 버전을 생성하시오."라는 질문을 던졌습니다. 다음은 전체 파일을 이용할 수 있는 몇 가지 예입니다. 여기:
{
"calls": [
{
"id": 5,
"type": "ABATEMENT",
"customer_input": "I need to report an abandoned property that has a major leak. Water is pouring out and flooding the sidewalk."
},
{
"id": 7,
"type": "AMR (METERING)",
"customer_input": "Can someone check my water meter? The digital display is completely blank and I can't read it."
},
{
"id": 15,
"type": "BTR/O (BAD TASTE & ODOR)",
"customer_input": "My tap water smells like rotten eggs. Is it safe to drink?"
}
]
}이제 우리는 대규모 언어 모델을 판단 기준으로 사용하여 보다 전통적인 평가로 실험을 설정할 수 있습니다.여기에서 전체 구현):
def classify(customer_input):
CALL_TYPES = [
"RESTORE", "ABATEMENT", "AMR (METERING)", "BILLING", "BPCS (BROKEN PIPE)", "BTR/O (BAD TASTE & ODOR)",
"C/I - DEP (CAVE IN/DEPRESSION)", "CEMENT", "CHOKED DRAIN", "CLAIMS", "COMPOST"
]
model = ChatAnthropic(model='claude-3-7-sonnet-latest')
prompt = f"""
You are a customer service AI for a water utility company. Classify the following customer input into one of these categories:
{', '.join(CALL_TYPES)}
Customer input: "{customer_input}"
Respond with just the category name, nothing else.
"""
# Get the response from Claude
response = model.invoke(prompt)
predicted_type = response.content.strip()
return predicted_type대규모 언어 모델(LLM)에 텍스트만 전달하면 반환된 추출된 클래스에서 실제 클래스 지식을 분리하여 비교할 수 있습니다.
def compare(customer_input, actual_type)
predicted_type = classify(customer_input)
result = {
"id": call["id"],
"customer_input": customer_input,
"actual_type": actual_type,
"predicted_type": predicted_type,
"correct": actual_type == predicted_type
}
return result이 글을 쓰는 시점에서 최신 모델인 Claude 3.7 Sonnet을 사용하여 전체 합성 데이터 세트에서 이를 실행한 결과, 호출의 91%가 정확하게 분류되어 매우 높은 성능을 보였습니다.
"metrics": {
"overall_accuracy": 0.91,
"correct": 91,
"total": 100
}이것이 실제 통화이고 우리가 해당 범주에 대한 사전 지식이 없다면, 우리는 여전히 9개의 잘못 분류된 통화를 찾기 위해 100개의 통화를 모두 검토해야 할 것입니다.
위의 강력한 의사결정 회로를 적용하면 유사한 정확도 결과를 얻을 수 있습니다. 자신 해당 답변에서, 이 경우 전체 정확도는 87%이지만, 신뢰도가 높은 답변의 정확도는 92.5%입니다.
{
"metrics": {
"overall_accuracy": 0.87,
"correct": 87,
"total": 100
},
"confidence_metrics": {
"high": {
"count": 80,
"correct": 74,
"accuracy": 0.925
},
"medium": {
"count": 18,
"correct": 13,
"accuracy": 0.722
},
"low": {
"count": 2,
"correct": 0,
"accuracy": 0.0
}
}
}신뢰도가 높은 답변에는 100%의 정확도가 필요하므로 아직 개선해야 할 부분이 많습니다. 이러한 접근 방식을 통해 더 깊이 파고들 수 있습니다. 이유 신뢰도가 높은 답변의 부정확성. 이 경우, 취약한 주장과 단순한 검증 기능으로는 모든 문제를 포착하지 못해 분류 오류가 발생합니다. 이러한 기능은 반복적으로 개선되어 신뢰도가 높은 답변에 대해 100% 정확도를 달성할 수 있습니다.
결과에 대한 신뢰도를 높이기 위한 필터링 시스템 개선
현재 시스템은 주 분석가와 예비 분석가가 동의할 경우 응답을 "높은 신뢰도"로 분류합니다. 더 높은 정확도를 얻으려면 "높은 신뢰도"로 간주되는 항목을 더욱 신중하게 선택해야 합니다.
# Modified high confidence logic
if (primary_result['call_type'] == backup_result['call_type'] and
primary_result['call_type'] is not None and
validation_result and
negative_check == 'yes' and
additional_validation_metrics > threshold):
return {'call_type': primary_result['call_type'], "confidence": "high"}추가적인 자격 기준을 추가함으로써 "높은 신뢰도" 결과의 수는 줄어들지만, 정확도는 높아질 것입니다. 이러한 필터링 시스템 개선은 오류를 줄이고 고품질로 분류된 데이터의 신뢰도를 높이는 것을 목표로 합니다.
추가 검증 기술: 분석 정확도 향상
데이터 검증 및 분석 프로세스를 개선하기 위한 몇 가지 다른 아이디어는 다음과 같습니다.
3차 분석기세 번째 독립적인 분석 방법을 추가합니다. 이 방법은 두 가지 다른 분석 방법의 결과와 세 번째 방법의 결과를 비교하여 추가적인 검증 단계를 제공함으로써 정확도를 높이고 오류 가능성을 줄입니다.
# Only mark high confidence if all three agree
if primary_result['call_type'] == backup_result['call_type'] == tertiary_result['call_type']:역사적 패턴 매칭결과를 과거에 유효한 결과와 비교합니다(벡터 탐색을 생각해 보세요). 이 기법은 신뢰할 수 있는 과거 데이터를 기준으로 삼고 현재 결과를 비교하여 편차나 불일치를 파악합니다. 이는 분석을 위한 일종의 "메모리"로 간주될 수 있으며, 이상 징후나 예상치 못한 사건을 감지하는 데 도움이 됩니다.
if similarity_to_known_correct_cases(primary_result) > 0.95:적대적 테스트입력값에 작은 변화를 적용하고 분류가 안정적으로 유지되는지 확인합니다. 이 접근법은 분류 시스템을 데이터의 작은 변화에 노출시켜 견고성과 안정성을 테스트하는 것을 목표로 합니다. 시스템이 이러한 변화에 매우 민감하다면, 잠재적인 약점이나 편향을 나타낼 수 있습니다.
variations = generate_input_variations(customer_input)
if all(analyze_call_type(var) == primary_result['call_type'] for var in variations):
LLM 추출 시스템에서의 인간 개입을 위한 일반 공식
- N = 총 실행 횟수(예시에서는 10,000회)
- p_1 = 기본 파서의 정확도(예시에서는 0.8)
- p_2 = 폴백 파서의 정확도(예시에서는 0.8)
- v = 스키마 검증기 효율성(예시에서는 0.7)
- n = 음수 검사기 효율성(예시에서는 0.6)
- H = 필요한 인적 개입 횟수
- E_final = 최종 감지되지 않은 오류
- m = 독립 감사인의 수
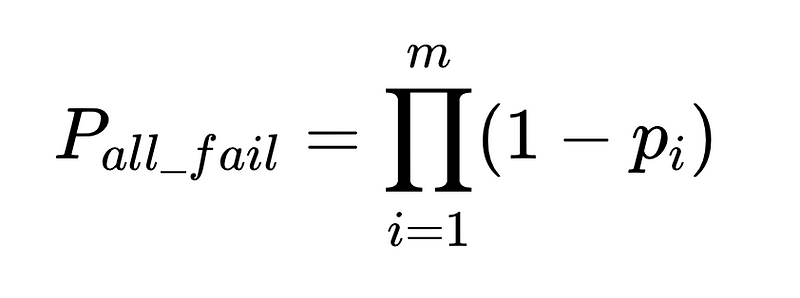
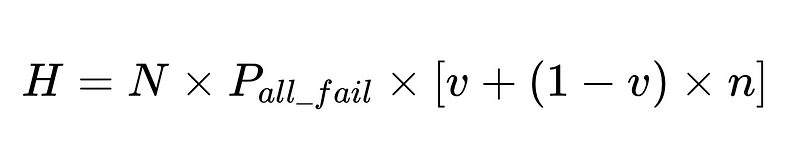
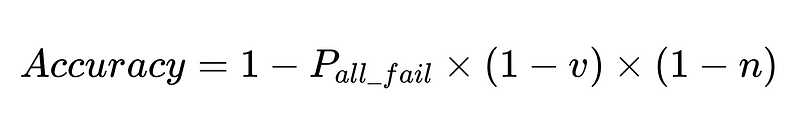
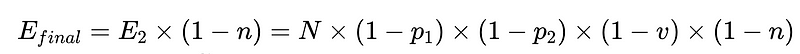
최적의 시스템 설계
이 방정식은 자연어 처리(NLP) 시스템의 정확도에 대한 중요한 통찰력을 보여줍니다.
- 파서를 추가하면 오버헤드는 줄어들지만 전반적인 정확도는 향상됩니다.
- 시스템 정확도는 다음과 같은 요인에 의해 제한됩니다.
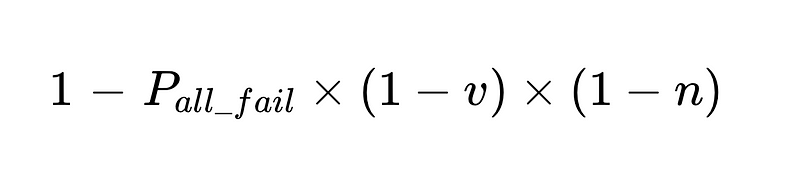
- 인간의 개입은 비례합니다 곧장 총 N번의 실행이 이루어졌습니다.
على سبيل المثال :
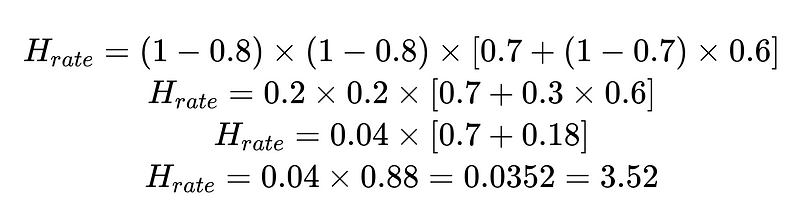
계산된 인간 개입률(H_rate)을 사용하여 솔루션의 효과를 실시간으로 추적할 수 있습니다. H_rate가 3.5% 이상으로 상승하기 시작하면 시스템에 문제가 있음을 알 수 있습니다. H_rate가 지속적으로 3.5% 미만으로 감소하면 최적화가 예상대로 작동하고 있음을 알 수 있습니다.
비용 함수
시스템 최적화에 도움이 되는 비용 함수를 생성할 수도 있습니다. 비용 함수는 시스템의 재무 성과를 평가하고 잠재적인 개선 영역을 파악하는 데 유용한 분석 도구입니다.
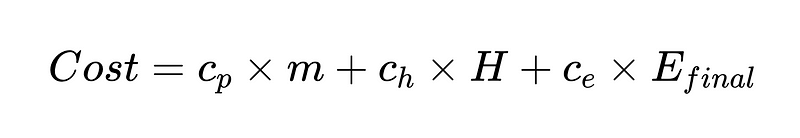
어디:
- c_p = 파서당 실행 비용(예시에서는 $0.10)
- m = 파서가 실행되는 횟수(예에서는 2 * N)
- H = 인간의 개입이 필요한 사례 수(예시에서 352개)
- c_h = 한 번의 인간 개입 비용(예: 4시간 @ 시간당 $50, $200)
- c_e = 감지되지 않은 오류 1개의 비용(예: $1000)
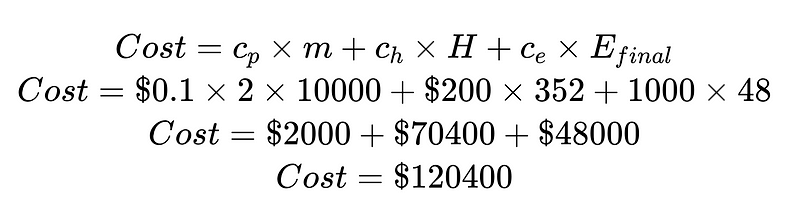
비용을 인적 개입 비용과 탐지되지 않은 오류 비용으로 나누면 전체 시스템을 개선할 수 있습니다. 이 예에서 인적 개입 비용(70,400달러)이 바람직하지 않고 비용이 많이 든다면, 신뢰도가 높은 결과를 얻는 데 집중할 수 있습니다. 탐지되지 않은 오류 비용(48,000달러)이 바람직하지 않고 비용이 많이 든다면, Plus 구문 분석기를 도입하여 탐지되지 않은 오류율을 줄일 수 있습니다.
물론, 비용 함수는 그것이 설명하는 상황을 개선하는 방법을 탐색하는 방법으로 가장 유용합니다.
위 시나리오에서 감지되지 않은 오류 수를 50% 줄이려면 E_final을 다음과 같이 설정합니다.
- p1과 p2 = 0.8,
- v = 0.7 및
- N = 0.6
우리에게는 세 가지 옵션이 있습니다:
- 정확도가 50%인 새로운 문법 파서를 추가하고 보조 파서로 포함시킵니다. 이 경우, Plus 문법 파서 실행 비용이 증가하고, 그에 따라 사람의 개입 비용도 증가한다는 단점이 있습니다.
- 현재 파서를 각각 10%씩 개선합니다. 이 파서들이 수행하는 작업의 난이도에 따라 가능할 수도 있고 불가능할 수도 있습니다.
- 감사 프로세스를 15% 개선합니다. 하지만 이 역시 인적 개입으로 인해 비용이 증가합니다.
AI 신뢰의 미래: 극도의 정밀성을 통한 신뢰 구축
AI 시스템이 비즈니스와 사회의 중요한 측면에 점점 더 통합됨에 따라, 특히 중요한 애플리케이션에서 최적의 정확성을 추구하는 것이 점점 더 중요해질 것입니다. AI 의사결정에 이러한 회로 기반 접근 방식을 도입함으로써, 효율적으로 확장될 뿐만 아니라 일관되고 안정적인 성능에서 비롯되는 깊은 신뢰를 얻는 시스템을 구축할 수 있습니다. 미래는 더욱 강력한 개별 모델이 아니라, 다양한 관점과 전략적 인간의 감독을 결합하는 신중하게 설계된 시스템에 달려 있습니다.
디지털 전자 제품이 신뢰할 수 없는 부품에서 진화하여 가장 중요한 데이터를 믿고 맡길 수 있는 컴퓨터를 만들어낸 것처럼, AI 시스템 또한 이제 비슷한 여정을 걷고 있습니다. 이 글에서 설명하는 프레임워크는 궁극적으로 미션 크리티컬 AI의 표준 아키텍처가 될 청사진을 제시합니다. 즉, 신뢰성을 약속할 뿐만 아니라 수학적으로도 이를 보장하는 시스템입니다. 이제 문제는 완벽에 가까운 정확도를 가진 AI 시스템을 구축할 수 있느냐가 아니라, 이러한 원칙을 가장 중요한 애플리케이션 전반에 얼마나 빨리 구현할 수 있느냐입니다.
댓글이 닫혔습니다.