

세상은 인공지능(AI) 불확실성의 온상처럼 보일지 모르지만, 실제로는 놀라울 정도로 많은 양의 분석, 벤치마킹, 테스트가 진행되고 있습니다. 이는 회사 자체뿐만 아니라 자체 순위를 결정하기 위해 만들어진 그룹에서도 진행됩니다.

이 그룹은 채팅봇이 수학 테스트를 완료하는 능력부터 모든 것을 테스트합니다.
이미지 만들기, 논리적인 설명을 제공하거나, 심지어 의학적 조언을 제공하거나, 단순히 그녀가 얼마나 감정적으로 지능적인지 보여줄 수도 있습니다.
이러한 다양한 테스트를 통해 모델은 각기 다른 영역에서 강점과 약점을 보여줍니다. 예를 들어, GPT-5 그는 과학적 추론에 뛰어나지만, 새로운 개념에 적응하는 능력은 제미니와 클로드보다 뒤처진다.
이러한 각 테스트는 AI 모델에 대한 새로운 정보를 제공하며, 다양한 상황에서 어떤 도구가 가장 효과적인지 파악하는 데 중요합니다. 하지만 종종 간과되는 지표가 하나 있습니다. 바로 어떤 AI 모델이 최고의 사용자 경험을 제공하는가입니다.
인간 분류 체계
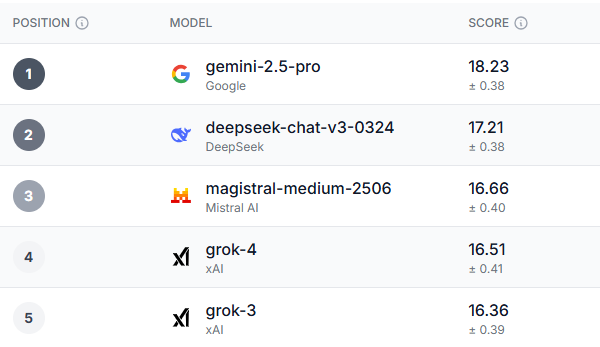
Prolific이라는 영국 기반 기술 회사가 만들었습니다. Humaine이라는 AI 리더보드Prolific은 AI가 작업을 완료하는 능력을 테스트하는 대신, 이러한 모델을 사용하여 다양한 사용자 경험을 테스트했습니다.
도구를 사용한 21,352명의 경험을 평가함으로써 그들은 전반적인 승자를 찾을 수 있었을 뿐만 아니라 연령, 위치(테스트는 영국과 미국 모두에서 수행됨), 정치적 신념에 따라 결과를 분석할 수 있었습니다.
여기에는 다음에 대한 개별 목록이 포함됩니다.
- 영국: 연령대
- 영국: 인종
- 영국: 정치적 관점
- 미국: 연령대
- 미국: 인종
- 미국: 정치적 관점
연구팀은 각 참가자에게 두 개의 별도 AI 모델과 상호 작용하여 비교하도록 한 뒤, 각 상호 작용에서 어느 모델이 더 나은 성과를 거두었는지 피드백을 제공하도록 요청했습니다.
이를 통해 성과 부문에서 전체 우승자와 순위표가 만들어졌을 뿐만 아니라 기본 작업 성과와 추론 부문에서도 별도의 순위가 매겨졌고, 의사소통, 회복력, 신뢰, 윤리 부문에서도 우승자가 나왔습니다.
결과는 어떻게 나타났나요?

철저한 검토 끝에, 전반적인 성능 부문뿐만 아니라 대부분의 하위 부문에서도 확실한 승자가 나타났습니다. Gemini 2.5-Pro는 테스트에 포함된 거의 모든 벤치마크에서 탁월한 성능을 보였습니다.
영국의 18~34세 청년층, 민주당 유권자, 미국의 55세 이상 유권자들은 다음과 같이 동의했습니다. 제미니 2.5 프로 전반적으로 가장 우수한 모델입니다. 모든 인구 통계가 Gemini보다 높은 순위를 기록한 유일한 영역은 신뢰, 윤리, 안전이었는데, 바로 Grok-3였습니다. 최근 AI 모델들이 직면한 안전 및 윤리 문제를 고려하면 다소 아이러니한 결과입니다.
흥미롭게도 Gemini 이후에 등장한 세 가지 모델은 Deepseek, Magistral Le Chat, 그록Deepseek은 올해 초 상당한 인기를 누렸지만, 최근 들어 주목을 받지 못하고 있습니다. 반면 Le Chat은 상대적으로 인기는 낮지만, 충성도 높은 팬층을 보유하고 있습니다.
그렇다면 세계적으로 유명한 ChatGPT는 이 모든 것에서 어떤 위치를 차지할까요? ChatGPT는 GPT-4.1 모델 중 가장 높은 평가를 받아 8위에 올라 최하위에 있습니다. 더 심각한 것은 클로드, 4회 대회 모두 전체 순위에서 각각 11위와 12위를 기록했습니다.
그러면 이 모든 것이 무엇을 의미할까요?
그렇다면 Gemini가 세계 최고의 AI 챗봇이라는 뜻인가요? ChatGPT를 버려야 한다는 뜻인가요…? 글쎄요, 정확히는 그렇지 않습니다.
이러한 결과가 반드시 해당 모델의 성능을 반영하는 것은 아닙니다. 대부분의 다른 지표를 기준으로 테스트했을 때, 일반적으로 상위에 표시되는 옵션은 ChatGPT, Gemini, Claude, Grok입니다.
하지만 이는 이러한 테스트에 중요한 추가 사항입니다. 이 테스트는 인간 경험의 관점에서 AI를 더 잘 이해하는 데 도움이 됩니다. 예를 들어, 르샤(Le Chat)는 표준 벤치마크에서 높은 점수를 받지는 못했지만, 경험과 신뢰성 측면에서 훌륭한 선택으로 자주 언급됩니다.
이번 테스트에서 Anthropic과 OpenAI의 성과는 이 수준에는 미치지 못했지만, Gemini와 Grok은 또 다른 강력한 성과를 보였습니다. 두 회사 모두 벤치마크에서 높은 점수를 자주 기록했으며, 이번 테스트에서도 높은 점수를 유지했습니다.
댓글이 닫혔습니다.