

사이버 보안 리더들은 해결 불가능한 질문들에 직면합니다. "올해 보안 침해 발생 가능성은 얼마나 될까요?" "비용은 얼마나 들까요?" 그리고 "이를 막기 위해 얼마나 많은 예산을 투입해야 할까요?"
그러나 오늘날 사용되는 대부분의 위험 모델은 데이터가 아닌 추측, 본능, 색상으로 구분된 위험 지도에 기반을 두고 있습니다.
사실, 나는 발견했다 PwC의 2025년 글로벌 디지털 신뢰 인사이트 연구 단 15%의 조직만이 정량적 위험 모델링을 상당한 정도로 사용합니다.
이 글에서는 기존 사이버보안 위험 모델이 왜 부족한지 살펴보고, 확률적 모델링과 같은 가벼운 통계 도구를 적용하면 어떻게 더 나은 해결책을 제공할 수 있는지 알아봅니다.

사이버 위험 모델링의 두 가지 주요 사고방식
사이버 위험 모델은 다음과 같습니다. 사이버 보안 위협과 정보 시스템, 데이터 또는 기업에 미치는 잠재적 영향을 분석, 평가 및 측정하는 데 사용되는 체계적인 프레임워크 또는 방법입니다.
정보 보안 전문가는 위험 평가 과정에서 주로 정성적 위험 모델링 방법과 정량적 위험 모델링 방법의 두 가지를 사용합니다. 사이버 위험의 정량적 모델링 전문적인 지식이 필요한 고급 기술입니다.
위험 평가를 위한 질적 모델
두 팀이 동일한 위험을 평가한다고 가정해 보겠습니다. 한 팀은 발생 가능성에 대해 4/5, 영향에 대해 5/5로 평가합니다. 다른 팀은 각각 3/5와 4/5로 평가합니다. 두 팀 모두 위험의 위치를 행렬에 표시합니다. 하지만 두 팀 모두 CFO의 질문, "이 문제가 실제로 발생할 가능성은 얼마나 되며, 이로 인해 우리에게 어떤 비용이 발생할 것인가?"에 답할 수 없습니다.
정성적 접근법은 주로 평가자의 직관에 기반한 주관적 위험 평가에 의존합니다. 정성적 접근법은 일반적으로 위험의 발생 가능성과 영향을 1~5점과 같은 순서 척도로 평가합니다.
다음으로, 위험이 순위 척도에서 어디에 위치하는지 파악하기 위해 위험 매트릭스에 위험이 위치합니다.
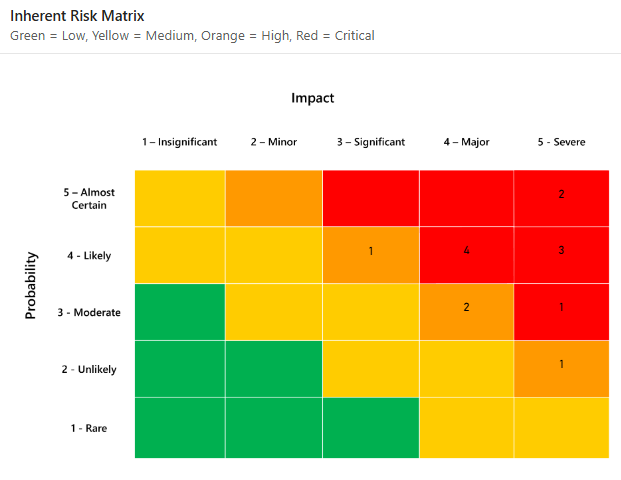
두 가지 순서형 척도는 발생 가능성과 영향도를 기준으로 가장 중요한 위험의 우선순위를 정하는 데 도움이 되도록 종종 곱해집니다. 언뜻 보기에 이는 타당해 보입니다. 정보 보안에서 일반적으로 사용되는 위험의 정의는 다음과 같습니다.
[위험도 = 가능성 } 곱하기 영향도]
그러나 통계적 관점에서 볼 때, 정성적 위험 모델링에는 매우 중요한 위험이 수반됩니다.
이러한 위험 중 첫 번째는 순서형 척도의 사용입니다. 순서형 척도에 숫자를 부여하면 모델에 대한 수학적 뒷받침이 있는 것처럼 보이지만, 이는 단지 환상일 뿐입니다.
순서형 척도는 단순히 라벨일 뿐입니다. 두 척도 사이에는 정해진 거리가 없습니다. 영향도가 "2"인 위험과 영향도가 "3"인 위험 사이의 거리는 정량화할 수 없습니다. 순서형 척도의 라벨을 "A", "B", "C", "D", "E"로 변경해도 아무런 차이가 없습니다.
이는 결국 정성적 모델링을 사용할 때 위험 공식에 결함이 있음을 의미합니다. "B"의 확률에 "C"의 효과를 곱한 값을 계산하는 것은 불가능합니다.
또 다른 주요 함정은 불확실성을 모델링하는 것입니다. 사이버 위험을 모델링할 때, 우리는 불확실한 미래 사건을 모델링하는 것입니다. 실제로는 다양한 결과가 발생할 수 있습니다.
사이버 위험을 단일 지점 추정치(예: "20/25" 또는 "높음")로 분류하는 것은 "연간 손실이 가장 클 가능성이 높은 것은 1만 달러"와 "10만 달러 이상의 손실이 발생할 확률이 5%"라는 중요한 차이점을 포착하지 못합니다.
정량적 위험 모델링: 고급 분석
위험 평가를 수행하는 팀을 상상해 보세요. 그들은 10만 달러에서 1천만 달러까지 다양한 결과를 예측합니다. 몬테카를로 시뮬레이션을 실행하여 연간 손실이 100만 달러를 초과할 확률은 10%이고, 예상 손실은 48만 달러입니다. 이제 CFO가 이렇게 질문합니다. "이런 일이 일어날 가능성은 얼마나 되며, 비용은 얼마나 들까요?"팀은 직감뿐만 아니라 데이터로도 대응할 수 있습니다.
이 접근 방식은 모호한 위험 분류에서 대화를 전환합니다. 가능성과 잠재적인 재정적 영향임원들이 이해하는 언어.
통계학에 대한 배경 지식이 있다면 특히 다음 개념이 눈에 띄어야 합니다.
개연성.
사이버 보안 위험 모델링은 본질적으로 특정 사건의 발생 가능성과 발생 시 그 영향을 정량화하려는 시도입니다. 이를 통해 몬테카를로 시뮬레이션과 같은 다양한 통계 도구를 활용할 수 있으며, 이는 순서형 측정 방식보다 불확실성을 훨씬 더 효과적으로 모델링할 수 있습니다.
양적 위험 모델링은 통계적 모델을 사용하여 손실에 대한 달러 가치를 할당하고 이러한 손실 사건이 발생할 확률을 모델링하여 미래의 불확실성을 포착합니다.
정성적 분석은 때때로 가장 가능성 있는 결과를 대략적으로 나타낼 수 있지만, 드물지만 영향력이 큰 사건인 "롱테일 리스크"와 같은 불확실성의 전체 범위를 포착하는 데는 실패합니다.
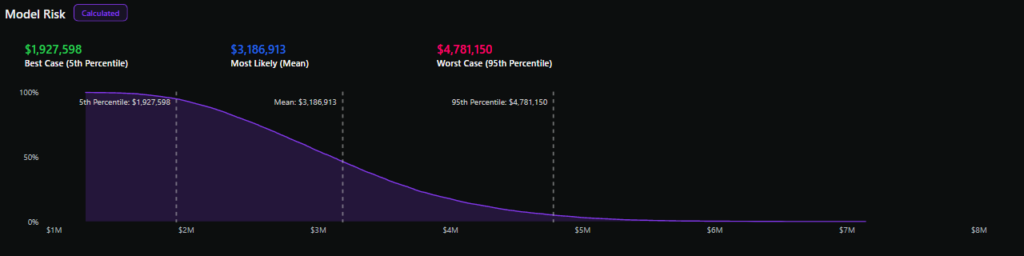
손실 초과 곡선은 y축에 주어진 연간 손실 금액을 초과할 확률을 표시하고, x축에 다양한 손실 금액을 표시하여 아래로 기울어진 선을 형성합니다.
손실 초과 곡선에서 5번째 백분위수, 중간값, 95번째 백분위수 등 다양한 백분위수를 추출하면 90% 신뢰도로 위험에 따른 잠재적 연간 손실에 대한 아이디어를 얻을 수 있습니다.
정성적 분석의 단일 지점 추정치는 평가자의 판단 정확도에 따라 가장 발생 가능성이 높은 위험에 근접할 수 있는 반면, 정량적 분석은 드물지만 여전히 발생할 가능성이 있는 위험(이를 "롱테일 위험"이라고 함)까지도 포함하여 결과의 불확실성을 포착합니다.
사이버 위험을 넘어: 사이버 보안 위험 모델 개선
정보 보안 위험 모델을 개선하려면 외부, 특히 다른 분야에서 사용되는 기술을 살펴봐야 합니다. 위험 모델은 금융, 보험, 항공 안전, 공급망 관리 등 다양한 분야에서 크게 발전해 왔습니다. 이러한 분야는 사이버 보안에 적용할 수 있는 귀중한 통찰력을 제공합니다.
재무팀은 유사한 베이지안 통계를 사용하여 투자 포트폴리오 위험을 관리하는 모델을 사용합니다. 보험팀은 정교한 보험계리 모델을 사용하여 위험을 모델링합니다. 항공 산업은 확률론적 모델을 사용하여 시스템 장애 위험을 모델링합니다. 공급망 관리팀은 확률론적 시뮬레이션을 사용하여 위험을 모델링합니다. 이러한 방법론은 효과적인 사이버 위험 모델을 개발하는 데 탄탄한 기반을 제공합니다.
도구는 이미 존재합니다. 수학적 기반은 잘 이해되고 있으며, 다른 산업에서도 이미 그 길을 개척했습니다. 이제 사이버 보안 분야에서 정량적 위험 모델을 도입하여 더 나은 정보에 기반한 의사 결정을 내리고, 사이버 보안 전략을 개선하며, 잠재적 손실을 줄여야 할 때입니다. 이러한 정량적 모델을 도입하는 것은 더욱 효과적인 사이버 위험 관리를 향한 중요한 발걸음을 의미합니다.
이슬람교
| 뉴올리언스 지도 | 모든 것의 균형 |
| 순서형 척도(1-5) | 확률적 모델링 |
| 개인적 직관 | 알렉산드리아의 종교 |
| 단일 평가 지점 | 위험 분포 |
| 히트맵과 색상 코드 | 손실 초과 곡선 |
| 드물지만 심각한 이벤트는 무시합니다. | 롱테일 리스크를 포착합니다 |
댓글이 닫혔습니다.