

요약:
- Google은 새로운 Gemini 2.0 Flash 베타를 사용하여 기본 이미지 생성 및 편집 기능을 출시했습니다.
- 이 기능은 현재 AI Studio에서 무료로 제공되며, 간단한 텍스트 명령을 사용하여 일련의 조정된 이미지를 생성하고 편집할 수 있습니다.
- 요소를 제거하거나 추가하고, 텍스트를 삽입하고, 이미지에 색상을 입히고, 시각적 스토리를 만드는 등 다양한 작업이 가능합니다.
AI 분야에서 "본질적으로 멀티모달"이라는 용어가 1년 넘게 등장해 왔지만, 기업들은 지금까지 AI 모델의 멀티모달 잠재력을 최대한 활용하는 데 소극적이었습니다. 구글이 마침내 최신 모델인 "제미니 2.0 플래시 익스페리멘탈"을 출시했습니다. 원본 이미지를 생성하고 편집하는 기능여기요.
이제 이미지 생성의 의미가 무엇인지 궁금하실 겁니다. AI 이미지 생성 기능은 ChatGPT와 같은 모든 주요 AI 챗봇에서 한동안 지원되어 왔습니다. ChatGPT나 Gemini에서 AI 이미지를 생성할 때, Dall-E 3나 Imagen 3와 같은 특수 전파 기반 모델에 명령을 전달합니다. 이러한 모델은 이미지 기반으로 학습되며 이미지 생성 전용으로 설계되었습니다. 즉, 기본 AI 모델의 일부가 아니라 확장된 기능입니다.
그러나 다음과 같은 언어적 시각 모델은 쌍둥이 자리 기본적으로 멀티모달(multimodal) 기능을 갖추고 있어 텍스트와 이미지를 모두 네이티브로 이해하고, 생성하고, 수정할 수 있습니다. 현재까지 어떤 기술 회사도 이 기능을 사용자에게 제공하지 않았습니다. OpenAI는 2024년에 GPT-4o를 통해 네이티브 이미지 생성 기능을 시연했지만, 다시 한번 출시되지는 않았습니다.
 원본 이미지 생성 기능을 사용하면 다음과 같은 이점을 얻을 수 있습니다. 더 나은 일관성 멀티모달 모델은 다양한 미디어의 방대한 데이터 세트를 기반으로 학습됩니다. 결과적으로 이러한 모델은 개념에 대한 이해도가 높아지고 세상에 대한 더 폭넓은 지식을 보여줍니다.
원본 이미지 생성 기능을 사용하면 다음과 같은 이점을 얻을 수 있습니다. 더 나은 일관성 멀티모달 모델은 다양한 미디어의 방대한 데이터 세트를 기반으로 학습됩니다. 결과적으로 이러한 모델은 개념에 대한 이해도가 높아지고 세상에 대한 더 폭넓은 지식을 보여줍니다.
이미지 생성 외에도 간단한 텍스트 명령을 사용하여 이미지를 원활하게 편집할 수 있습니다. 예를 들어, 이미지를 업로드하고 모델에 선글라스 추가, 굵은 텍스트 삽입, 객체 제거 등의 작업을 요청할 수 있습니다. 새로운 명령이 있을 때마다 전체 이미지를 재생성하는 확산 모델과 달리, 네이티브 멀티미디어 모델은 여러 번의 편집 과정에서 일관성을 유지합니다.
Gemini 2.0 Flash 데모로 이미지 만들기
현재 기본 이미지 생성 기능은 일반 사용자에게 제공되지 않습니다. 기본 이미지 생성 기능이 포함된 Gemini 2.0 Flash 베타 버전은 Google AI Studio 플랫폼에서만 제공됩니다(방문) 무료입니다.
AI Studio에서 모델을 미리 본 후, 가까운 시일 내에 모든 사용자가 사용할 수 있도록 Gemini에 출시될 예정입니다. 하지만 저는 이미지 생성 기능을 탑재한 새로운 Gemini 모델을 사용해 보았는데, 정말 흥미로운 경험이었습니다.
먼저, 쌍둥이자리의 이미지 생성 능력의 일관성을 시각적으로 보여주는 시연으로 시작했습니다. 쌍둥이자리에게 오믈렛 만드는 방법을 시각적으로 보여주고, 각 단계마다 이미지를 만들어 달라고 부탁했습니다.
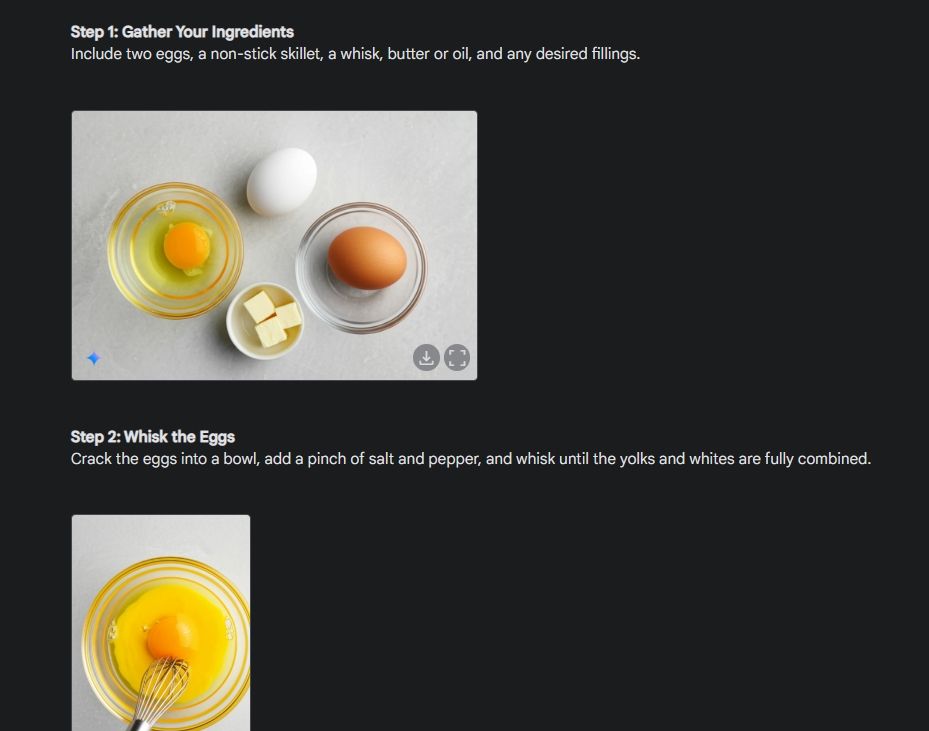
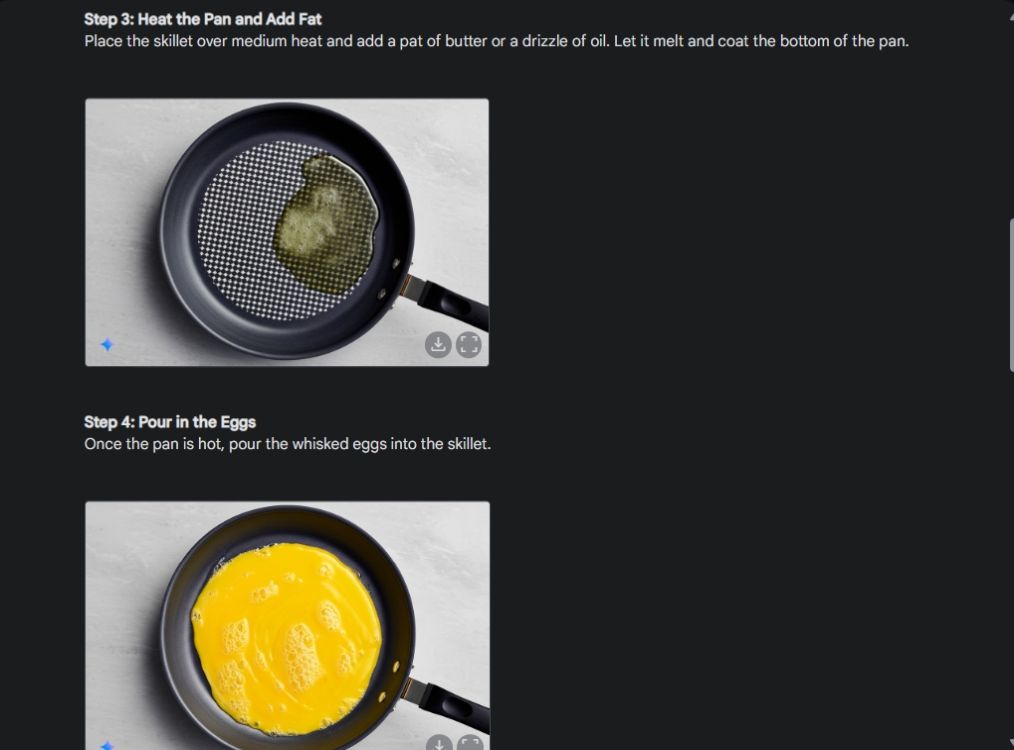

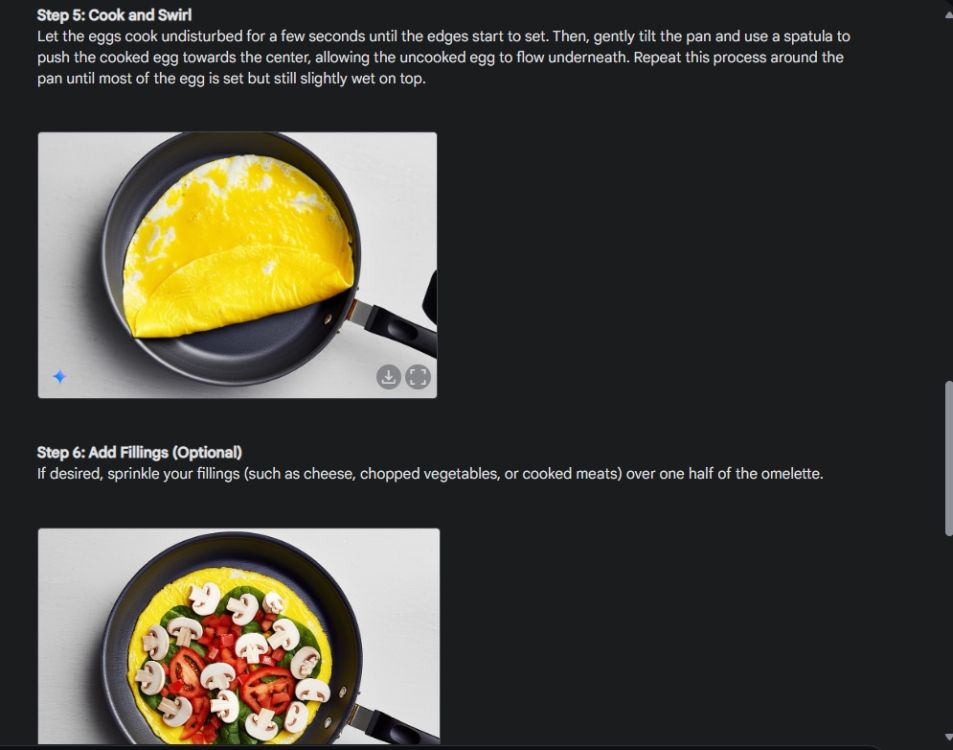
보시다시피, 이미지 전체에서 결과가 매우 일관되고 오류도 없습니다. 두 번째 이미지에서는 그릇 모양도 똑같습니다. 마지막으로, 이미지를 1024 x 680 해상도로 다운로드할 수 있습니다. 이렇게 하면 원하는 대로 시각적 가이드를 만들 수 있습니다.
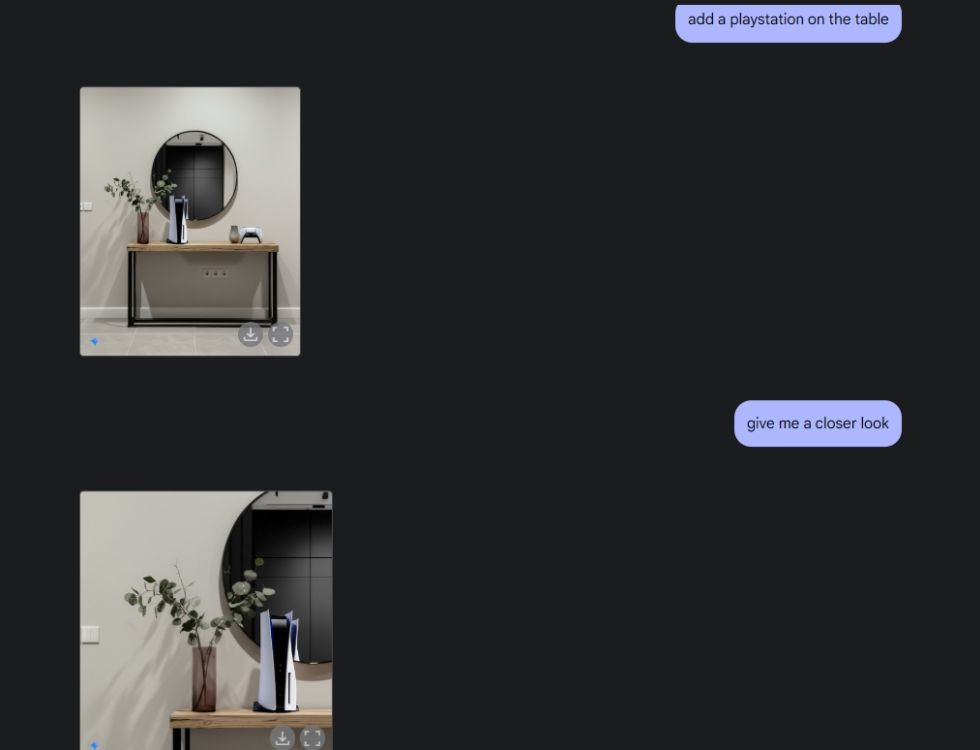
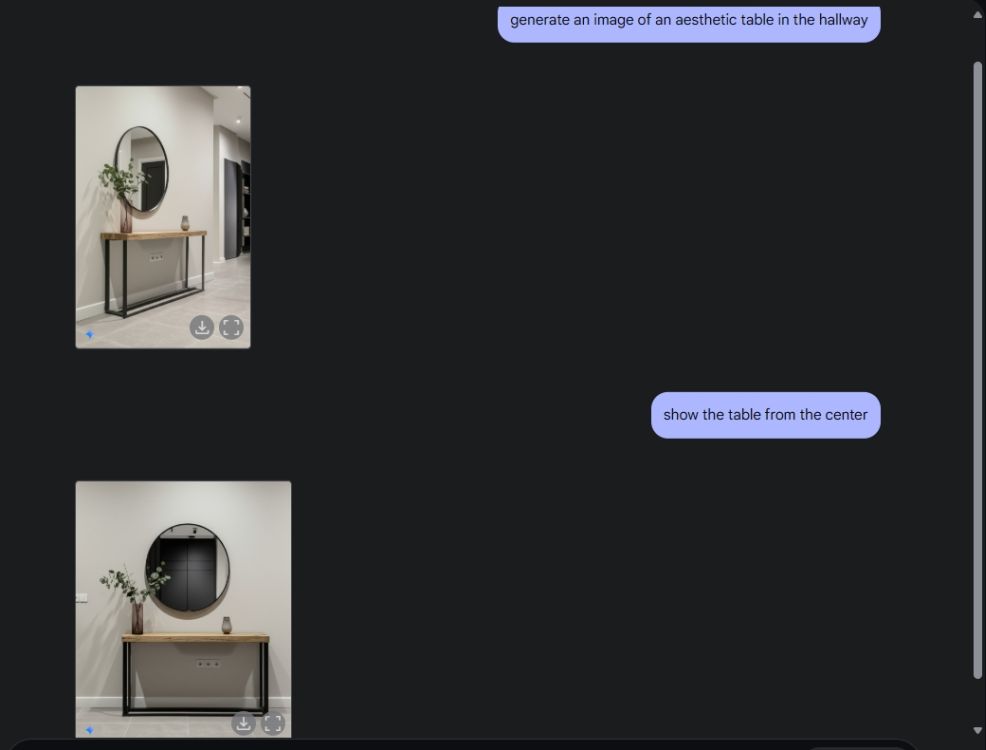
다음으로, 제미니에게 아름다운 테이블 이미지를 만들어 달라고 한 후, 중앙 카메라 각도에서 테이블을 보도록 했습니다. 제미니는 완벽하게 해냈습니다. 그다음, 제미니에게 플레이스테이션을 테이블에 올려놓고 자세히 살펴보라고 했습니다. 제미니 역시 완벽하게 해냈습니다. 아래에서 보시다시피, AI 모델은 뒤쪽 거울에 비친 PS5의 모습도 포착했습니다.
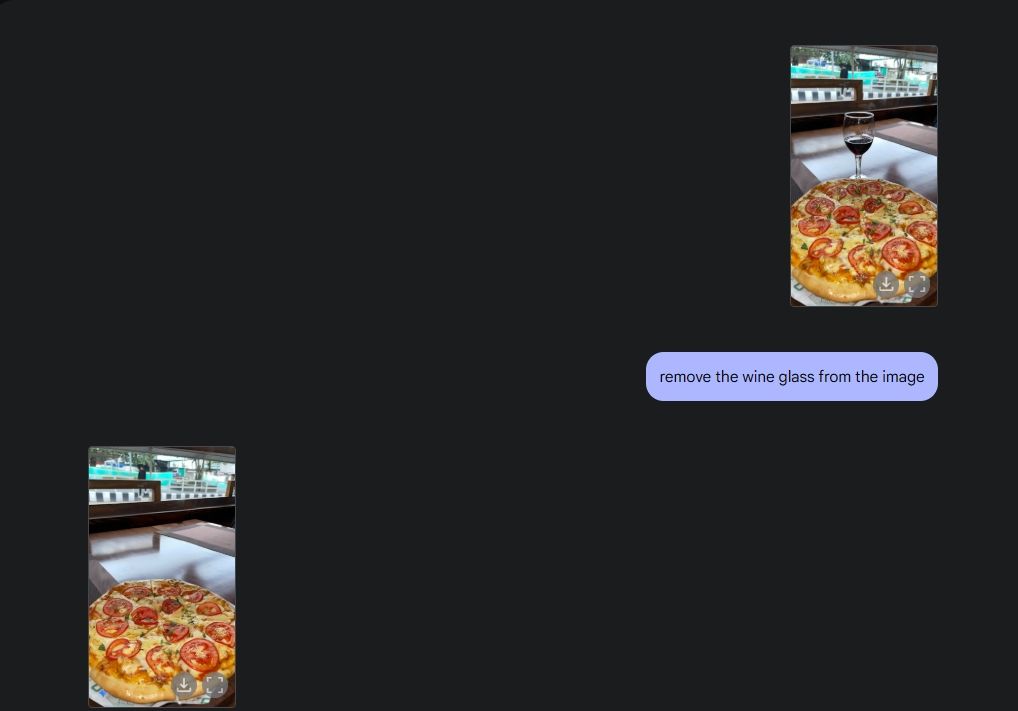
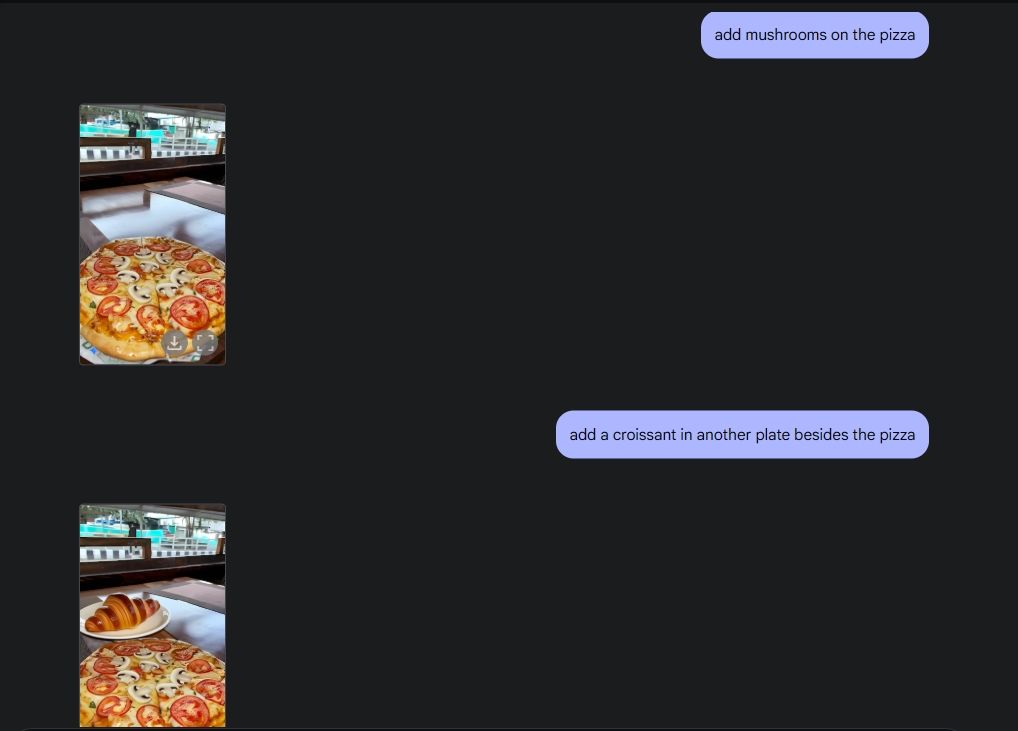
원래 사진 편집 기능을 시연하기 위해 갤러리에서 사진을 업로드하고 Gemini 2.0에게 테이블에서 와인 잔을 치우라고 했습니다. 그런 다음 Gemini에게 피자에 버섯을 추가하라고 했는데, 아주 잘 되었습니다. 그런 다음 Gemini에게 크루아상을 추가하라고 했습니다. 이렇게 Gemini의 멀티미디어 기능 덕분에 AI 사진 편집 기능이 완벽하게 구현되었습니다.
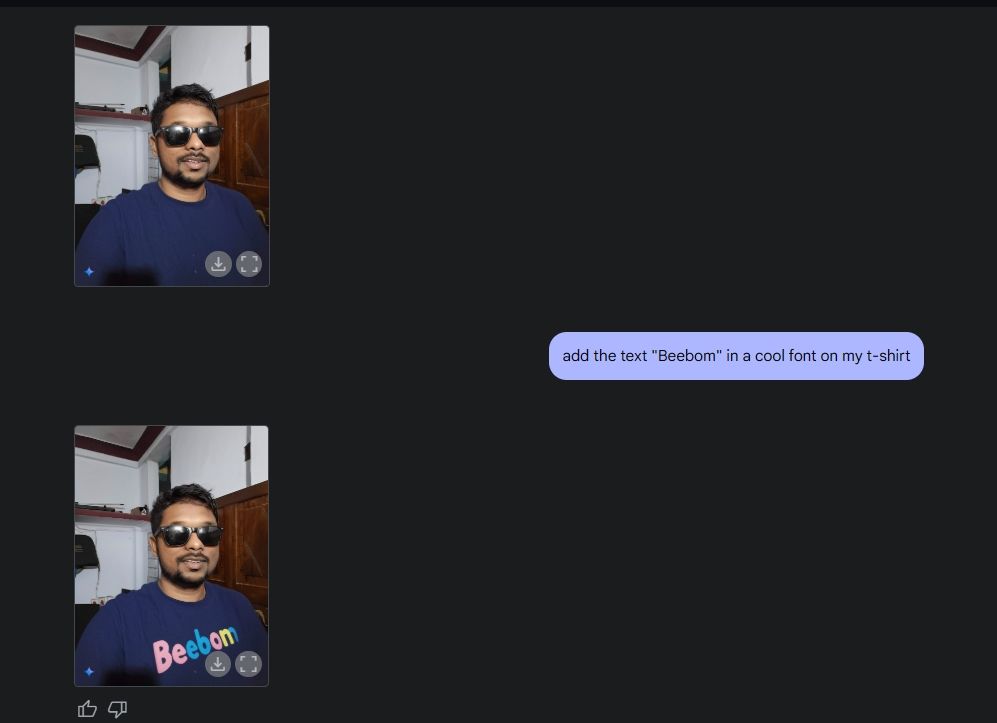
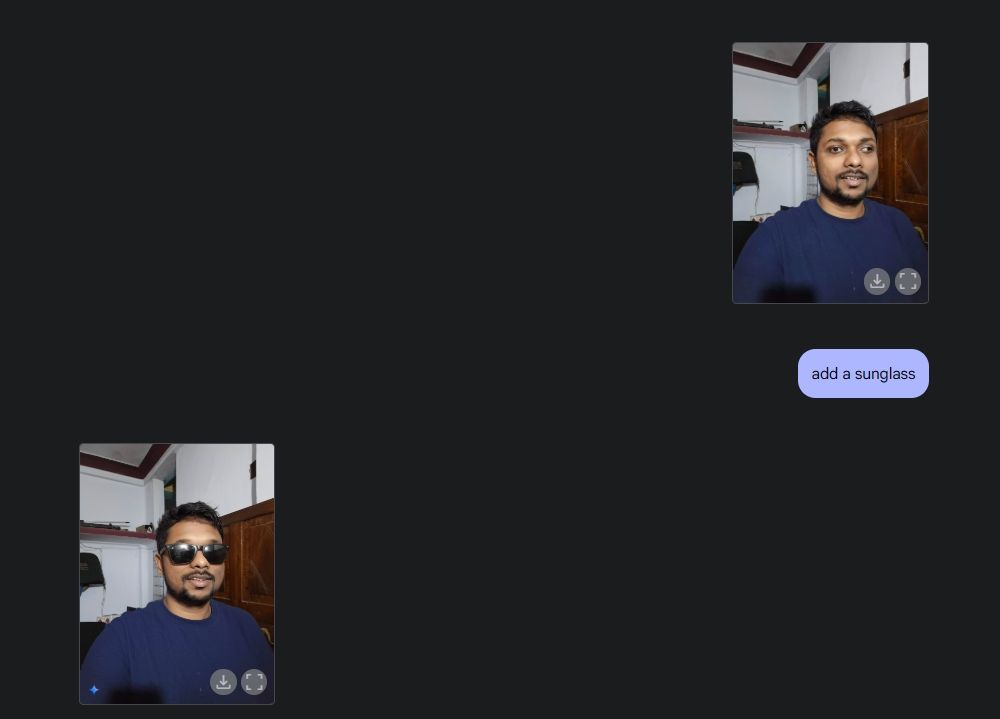
다음으로, 제 사진을 업로드하고 쌍둥이자리에게 선글라스를 달아달라고 부탁한 다음, 셔츠에 "비봄"이라는 문구를 넣어달라고 부탁했습니다. 두 가지 모두 정말 잘 구현되었습니다.
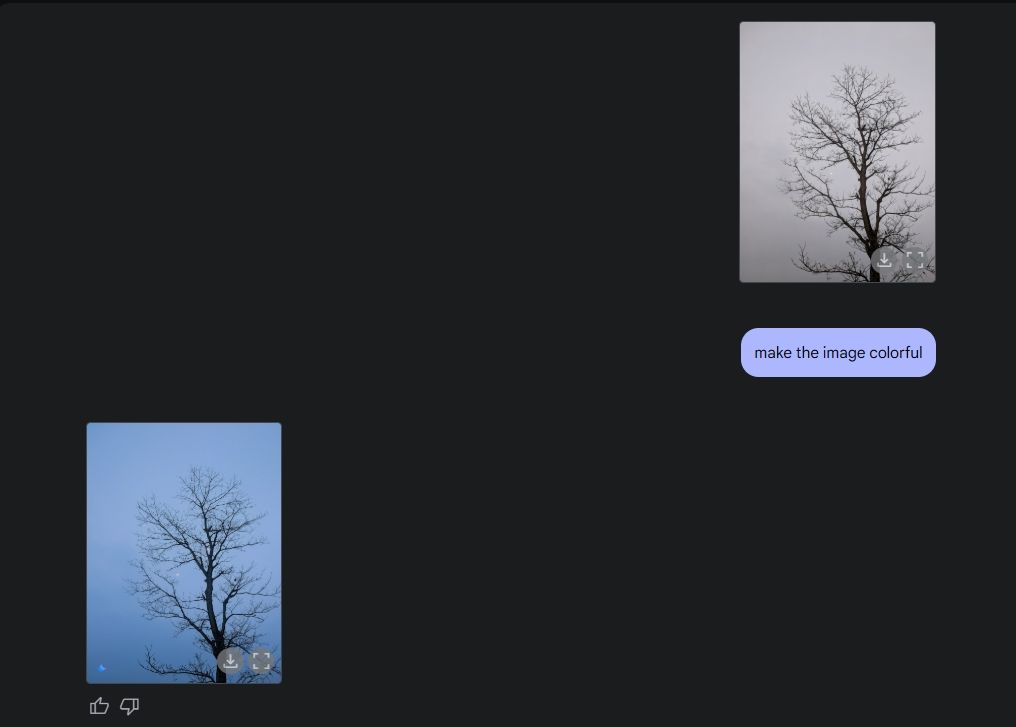
마지막으로 제미니에게 사진에 컬러링을 부탁했는데, 역시 훌륭하게 해냈어요. 사진이 전보다 훨씬 좋아졌죠. 이상한 버그나 왜곡, 누락된 부분 없이요.
Gemini의 새로운 멀티미디어 기능을 다양하게 실험해 볼 수 있습니다. Google은 네이티브 이미지 생성 및 편집 기능을 훌륭하게 구현했으며, 앞으로 몇 주 동안 Gemini를 더욱 심도 있게 사용하며 그 한계를 시험해 볼 계획입니다.
비디오 제작용 Veo 2와 특수 이미지 생성용 Imagen 3가 출시되면서 구글은 AI 텍스트 생성뿐만 아니라 여러 분야에서 OpenAI를 앞지른 것으로 보입니다. 따라서 OpenAI가 ChatGPT를 통해 선두 자리를 되찾기 위해 어떤 행보를 보일지 주목됩니다.
댓글이 닫혔습니다.