

최신 트랜스포머 비전 모델은 2D 및 3D 객체 감지 성능을 향상시키기 위해 노이즈를 추가합니다. 이 글에서는 이 메커니즘의 작동 원리를 살펴보고, 학습 과정에서 노이즈 제거와 같은 기법을 사용하는 것을 중심으로 객체 감지 모델의 정확도 향상에 미치는 영향을 논의합니다.

초기 비전을 위한 변압기 모델
객체 감지를 위한 최초의 트랜스포머 아키텍처 중 하나인 DETR – DEtection TRansformer(Carion, Massa et al., 2020)는 학습된 인코더-디코더 쿼리를 사용하여 이미지 토큰에서 감지 정보를 추출했습니다. 이러한 쿼리는 무작위로 초기화되었으며, 아키텍처는 이러한 쿼리가 앵커 유사 객체를 학습하도록 강제하는 어떠한 제약 조건도 부과하지 않았습니다. Faster-RCNN과 유사한 결과를 얻었지만, 느린 수렴 속도라는 단점이 있었습니다. 학습에 500번의 에포크가 필요했습니다(DN-DETR, Li et al., 2024). 최근 DETR 기반 아키텍처는 변형 가능한 풀링을 사용하여 쿼리가 이미지의 특정 영역에만 집중할 수 있도록 했습니다(Zhu et al., Deformable DETR: Deformable Transformers For End-To-End Object Detection, 2020). 반면 다른 아키텍처(Liu et al., DAB-DETR: Dynamic Anchor Boxes Are Better Queries For DETR, 2022)는 초기 쿼리에 인코딩된 공간 앵커(앵커 기반 CNN과 유사하게 k-평균을 사용하여 생성)를 사용했습니다. 스킵 연결은 변압기 디코더 블록이 앵커에서 회귀 값으로 상자를 학습하도록 했습니다. 변형 가능한 어텐션 레이어는 사전 인코딩된 앵커를 사용하여 이미지에서 공간적 특징을 샘플링하고 이를 사용하여 어텐션 토큰을 생성합니다. 학습 중에 모델은 사용할 최적의 앵커를 학습합니다. 이 접근 방식은 모델이 쿼리에서 상자 크기와 같은 특징을 명시적으로 사용하도록 가르칩니다.
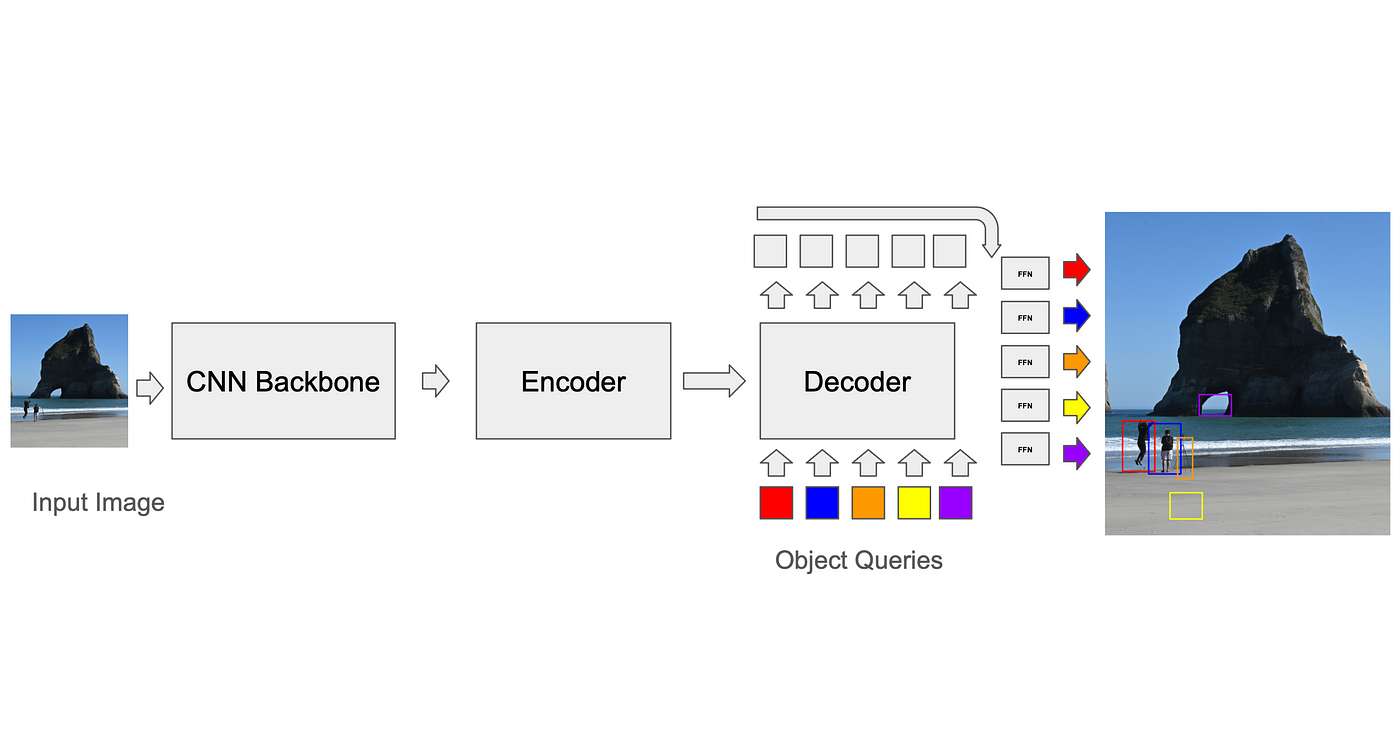
예측과 실제 사실의 일치: 이진 일치 알고리즘
손실을 계산하려면 학습기가 먼저 모델의 예측값을 실제 값(GT) 상자와 매칭해야 합니다. 앵커 기반 CNN은 이 문제에 대해 비교적 쉬운 해결책을 제시하지만(예: 각 앵커는 학습 중에 해당 복셀의 GT 상자에만 매칭될 수 있으며, 추론 및 비최대 억제 기법을 사용하여 중복 검출을 제거합니다), DETR에서 개발한 변환기 표준은 헝가리안 알고리즘이라는 이진 매칭 알고리즘을 사용하는 것입니다. 알고리즘은 각 반복에서 예측값과 실제 값 사이의 최적의 매칭(모든 상자에 대해 합산된 상자 모서리 사이의 평균 제곱 거리와 같은 비용 함수를 최적화하는 매칭)을 찾습니다. 그런 다음 예측값-실제 값 쌍 사이의 손실을 계산하고 역전파할 수 있습니다. 과대 예측(GT 매칭이 없는 예측)은 별도의 손실을 발생시켜 신뢰도 점수를 낮추게 합니다. 이 과정은 모델 정확도를 높이고 오류를 줄이는 데 필수적입니다.
문제
헝가리안 알고리즘의 시간 복잡도는 o(n³)입니다. 흥미롭게도, 이것이 반드시 학습 품질의 병목 현상은 아닙니다. Fenoaltea 외 연구진의 저서 『The Stable Marriage Problem: An Interdisciplinary Review From The Physicist's Perspective』(2021)에 따르면, 이 알고리즘은 불안정합니다. 즉, 목적 함수의 작은 변화가 매칭 결과에 큰 변화를 가져와 쿼리 학습 목표의 일관성을 떨어뜨릴 수 있습니다. 트랜스포머 학습의 실질적인 의미는 객체 쿼리가 객체 간을 이동할 수 있어 수렴에 필요한 최적의 특징을 학습하는 데 오랜 시간이 걸린다는 것입니다. 다시 말해, 이 알고리즘의 불안정성은 학습 과정의 진동으로 이어져 최적의 결과에 도달하는 데 더 오랜 시간이 걸립니다.
DN-DETR(노이즈 제거를 통한 객체 감지)
Li 등은 불안정한 매칭 문제에 대한 우아한 솔루션을 제안했는데, 이는 나중에 DINO, Mask DINO, Group DETR 등 다른 많은 연구에 채택되었습니다.
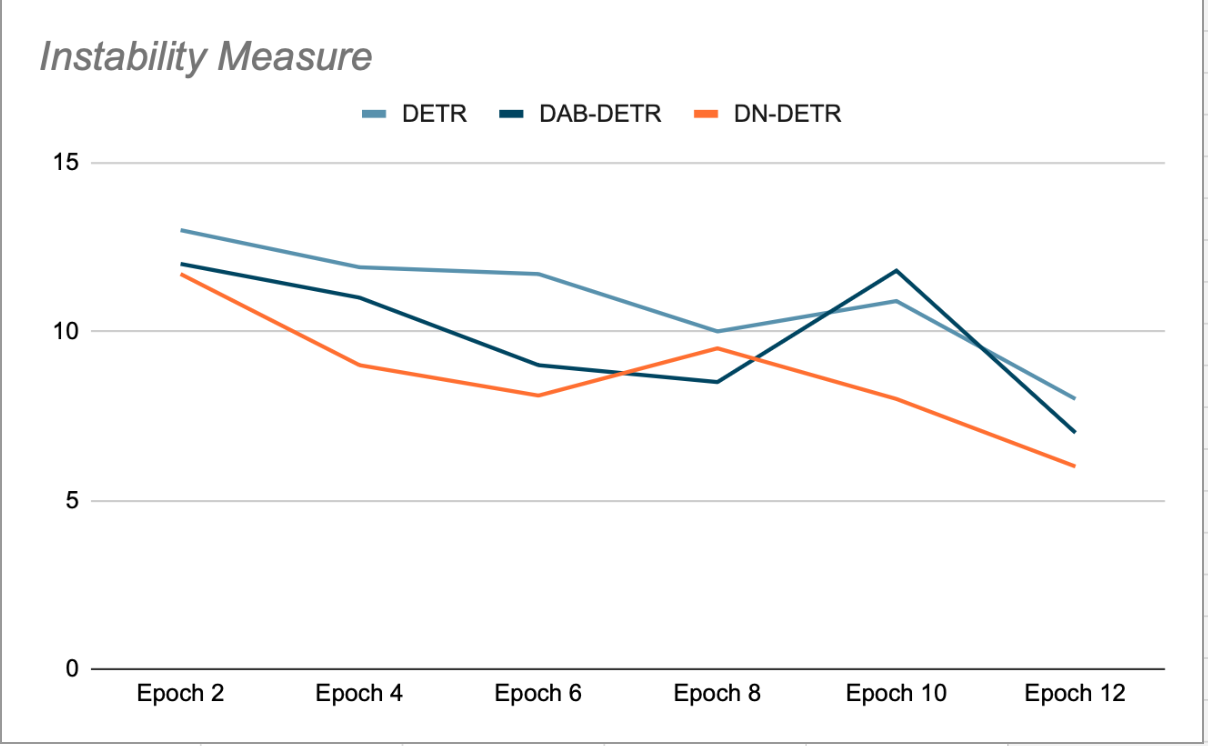
DN-DETR의 주요 아이디어는 훈련을 강화하는 것입니다. 경사가 쉬운 가상 피벗 포인트이 알고리즘은 매칭 과정을 생략합니다. 이는 훈련 과정에서 GT(진정한 지면) 타일에 소량의 노이즈를 추가하고, 이 노이즈 타일을 디코더 쿼리의 앵커로 사용하여 수행됩니다. DN 쿼리는 유기적 쿼리에서 마스킹되며, 그 반대의 경우도 마찬가지입니다. 이는 훈련에 방해가 될 수 있는 교차 어텐션을 방지하기 위함입니다. 이러한 쿼리에서 생성된 탐지는 이미 소스 GT 타일과 매칭되어 있으며, 이분 매칭이 필요하지 않습니다. DN-DETR의 저자들은 각 에포크의 마지막 검증 단계(노이즈 제거 기능이 꺼진 상태)에서 이 알고리즘이 DETR 및 DAB-DETR에 비해 모델 안정성을 향상시킨다는 것을 보여주었습니다. 즉, Plus 쿼리는 연속된 에포크에서 GT 객체와의 매칭에서 일관성을 유지합니다(그림 2 참조).
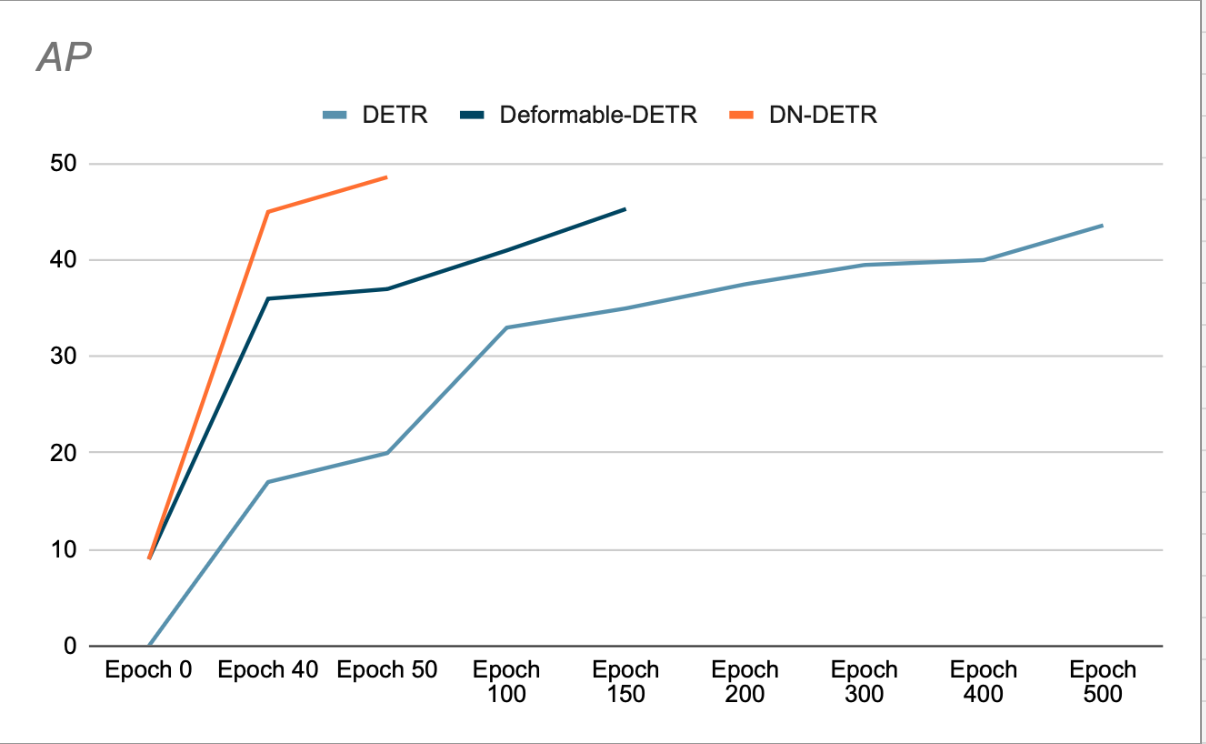
저자들은 DN을 사용하면 수렴 속도가 빨라지고 더 나은 탐지 결과를 얻을 수 있음을 보여줍니다(그림 3 참조). 제거 연구에 따르면 ResNet-1.9을 백본으로 사용했을 때 COCO 탐지 데이터셋의 AP(평균 정확도)가 이전 SOTA(DAB-DETR, AP 42.2%)에 비해 50% 증가했습니다.
DINO 및 대비 노이즈 제거
DINO는 이 아이디어를 더욱 발전시켜 노이즈 제거 메커니즘에 대조 학습을 추가합니다. 즉, 양성 예제 외에도 각 GT의 노이즈 제거된 두 번째 버전을 생성합니다. 이 버전은 양성 예제보다 GT에서 더 멀리 떨어져 있도록 수학적으로 구성됩니다(그림 4 참조). 이 버전은 학습을 위한 음성 예제로 사용됩니다. 모델은 "객체 없음" 클래스를 예측하는 것을 학습함으로써 기준 진실에 더 가까운 탐지를 받아들이고 더 멀리 떨어진 탐지를 거부하는 방식을 학습합니다.
또한, DINO는 대조적 잡음 제거(CDN)를 위한 다중 클러스터링을 지원합니다. 즉, 각 GT 객체에 대해 여러 개의 잡음 앵커를 사용하여 각 학습 반복에서 최대한의 성능을 이끌어냅니다.
DINO 저자는 CDN을 사용할 때 평균 정확도(AP)가 49%(COCO val2017 기준)라고 보고했습니다.
Sparse4Dv3와 같이 프레임 간에 객체를 추적해야 하는 최신 시간 모델은 CDN을 사용하고 시간적 잡음 제거 그룹을 추가합니다. 여기서 일부 성공적인 DN 앵커가 (학습된 비 DN 앵커와 함께) 후속 프레임에서 사용하기 위해 저장되므로 객체 추적에서 모델의 성능이 향상됩니다.

토론
노이즈 제거(DN)는 비전 트랜스포머 검출기의 수렴 속도와 최종 성능을 향상시키는 것으로 보입니다. 그러나 위에서 언급한 다양한 방법들의 발전을 살펴보면 다음과 같은 의문이 제기됩니다.
- DN은 학습 가능한 앵커를 사용하는 모델을 개선합니다. 하지만 학습 가능한 앵커가 정말 중요할까요? 그리고 DN이 학습 불가능한 앵커를 사용하는 모델도 개선할까요?
- DN이 학습에 기여하는 주요 요소는 이분 매칭을 우회하여 경사하강법의 안정성을 높이는 것입니다. 하지만 이분 매칭이 존재하는 주된 이유는 변환기 작업의 표준이 쿼리에 대한 공간적 제약을 피하는 것이기 때문인 것으로 보입니다. 따라서 쿼리를 특정 이미지 위치로 수동 제한하고 이분 매칭을 포기하거나 (또는 각 이미지 패치에서 개별적으로 실행되는 간소화된 버전의 이분 매칭을 사용하더라도) DN이 여전히 결과를 개선할 수 있을까요?
이러한 질문에 대한 명확한 답을 제공하는 연구는 아직 찾지 못했습니다. 제 가설은 학습 불가능한 앵커(앵커가 너무 희소하지 않은 경우)와 공간적으로 제한된 쿼리를 사용하는 모델은 1. 이진 매칭 알고리즘이 필요하지 않으며, 2. 앵커가 이미 알려져 있고 다른 임시 앵커에서 회귀를 학습해도 이득이 없기 때문에 DN 학습의 이점을 얻지 못한다는 것입니다.
앵커가 고정되어 있지만 분산되어 있다면 임시 앵커를 사용하면 하강하기가 더 쉬워지고 훈련 과정을 따뜻하게 시작할 수 있습니다.
Anchor-DETR(Wand et al., 2021)은 학습 가능한 앵커와 학습 불가능한 앵커의 공간 분포와 각 모델의 성능을 비교합니다. 제 생각에는 학습 가능성이 모델 성능에 큰 영향을 미치지는 않습니다. 두 방법 모두 헝가리안 알고리즘을 사용하므로, 이진 매칭을 포기하고도 성능을 유지할 수 있을지는 불분명합니다.
염두에 두어야 할 사항 중 하나는 추론에서 NMS를 피하는 데에는 생산적인 이유가 있을 수 있다는 것입니다. 이는 훈련에서 헝가리안 알고리즘을 사용하는 것을 장려합니다.
소음 제거가 실제로 중요한 부분은 어디일까요? 제 생각에는 추적 성추적 과정에서 모델은 비디오 스트림을 제공받으며, 연속된 프레임에 걸쳐 여러 객체를 감지하는 것뿐만 아니라 감지된 각 객체의 고유한 정체성을 유지해야 합니다. 시간 변환기 모델, 즉 비디오 스트림의 순차적 특성을 활용하는 모델은 개별 프레임을 독립적으로 처리하지 않습니다. 대신 이전 감지 데이터를 저장하는 뱅크를 유지합니다. 학습 과정에서 추적 모델은 가장 가까운 앵커에서 단순히 회귀하는 것이 아니라 이전 객체 감지(더 정확히는 이전 객체 감지와 관련된 앵커)에서 회귀하도록 권장됩니다. 이전 감지 데이터는 고정된 앵커 네트워크에 의해 제한되지 않으므로, DN이 유도하는 유연성이 유익할 가능성이 높습니다. 이러한 문제를 해결하는 향후 연구를 기대합니다.
노이즈 제거와 비전 트랜스포머에 대한 기여에 대한 내용은 여기까지입니다! 제 글이 마음에 드셨다면 딥 러닝과 머신 러닝에 대한 다른 글들도 읽어보세요. 컴퓨터 비전!
댓글이 닫혔습니다.